Planning for AI without LLMs
LLMs are transforming many areas of technology and beyond with capabilities that appear to be endless. However, although language-based AI technologies are undoubtedly extremely impressive, key frontiers of AI such as physical intelligence (i.e. robotics) and independent scientific discovery are still ahead of us. Are LLMs the right paradigm to get us there? Here I examine computations known as planning, which have long been at the centre of AI research, are a core part of animal intelligence, and are widely believed to be a crucial pillar of the aforementioned milestones. I ask whether LLMs are really suited to this space of problems and what alternative paths the field has in mind.
Introduction
AI technologies, and those built on Large Language Models (LLMs), are at the
centre of many polemical economic, political and cultural contemporary
discussions. One such discussion revolves around the trajectory of this
technology: how advanced will it be in one year, a decade, a century from now. These
analyses have swept up a range of ideas across economics, sociology, ethics and
computer science. Conventional concepts such as
Universal Basic Income - WikipediaUniversal basic income (UBI) is a social welfare proposal in which all members of a given population regularly receive a minimum income in the form of an unconditional transfer payment, i.e., without a means test or need to perform work.en.wikipedia.orgUniversal Basic Income
have a long history of association with imagined techno-utopias; other longstanding observations
like Jevon's Paradox - WikipediaIn economics, the Jevons paradox is said to occur when technological improvements that increase the efficiency of a resource's use lead to a rise, rather than a fall, in total consumption of that resource.
en.wikipedia.orgJevons paradox or
Moore's law - WikipediaMoore's law is the observation that the number of transistors in an integrated circuit doubles about every two years, originally observed by Gordon Moore in 1965.
en.wikipedia.orgMoore's law, seem to have
found new analogies with an AI flavour; while the outright bizarre has also managed
to find a home in this discourse, for instance in the adaptation of
Pascal's Wager - WikipediaPascal's wager is a philosophical argument that posits that individuals essentially engage in a life-defining gamble regarding the belief in the existence of God.
en.wikipedia.orgPascal's wager to
Roko's Basilisk - WikipediaRoko's basilisk is a thought experiment which posits that an all-powerful artificial intelligence from the future could retroactively punish those who did not help bring it into existence.
en.wikipedia.org'Roko's Basilisk'. For a long
time these speculations have exclusively been the domain of science fiction writers
and My Dated Predictions - Rodney BrooksRodney Brooks' predictions about the future of AI.
 rodneybrooks.comsubject-matter experts,
but recent advancements and the collective sense of imminence around the
potential impact of AI on security, labour markets, scientific discovery, and
beyond, have propelled these discussions firmly into the mainstream.
rodneybrooks.comsubject-matter experts,
but recent advancements and the collective sense of imminence around the
potential impact of AI on security, labour markets, scientific discovery, and
beyond, have propelled these discussions firmly into the mainstream.
Here, I am going to focus on one particular perspective on this set of
questions, namely the assertion that LLMs are fundamentally limited, and that
while an incredibly useful and possibly transformative tool, LLMs as a strategy
to achieve more general forms of intelligence are doomed to fail.
Large Language Models operate in the domain of text, of words, and do so impressively.
Ironically, in evolutionary terms, language is a late arrival to
our collective cognitive abilities: humans began hunting prey around
1 million years ago, and foraging for other foods long before that.
Modern language, on the other hand, with abstraction and complex grammar, emerged only around 50-100 thousand years ago.
Animals far less evolved than humans understand on an intuitive level concepts like friction and gravity.
Within the lifespan of a human too, language abilities emerge relatively late.
Although babies may splutter out their first words within a year, structured communication abilities
are typically attained around 4-7 years old. On the other hand, cognitive features like
grasping Object Permanence - WikipediaObject permanence is the understanding that objects continue to exist even when they cannot be observed.en.wikipedia.orgobject permanence and early memory
formations are reached within months of birth.
Yet true intelligence requires this understanding of physics—grounded in the real world;
LLMs have skipped ahead, mastering language despite not being equipped with the right
properties to exhibit other forms of intelligence that are second nature to humans and even many animals.
The above arguments have been made by various researchers, most notably Turing award winner
Yann LeCun, who recently Computer scientist Yann LeCun: 'Intelligence really is about learning'Lunch with the FT: Yann LeCun
 ft.comleft
Meta—reasons for which include disagreement related to the topics
here—to start his own AI lab focused on a different machine learning paradigm
known as World Models (more on this later).
ft.comleft
Meta—reasons for which include disagreement related to the topics
here—to start his own AI lab focused on a different machine learning paradigm
known as World Models (more on this later).
This contrarian perspective might raise eyebrows among many following current
AI hype cycles, but for those familiar with the history of these technologies,
disagreement of this kind should come as no surprise.
Each generation of AI progress since its formal inception as a field in a
notorious 1956 Dartmouth
conference has been accompanied by seemingly equal parts
excitement and cynicism from within the research community. This typically
coincides with a new wave of predictions concerning the timeline to passing
increasingly specialized versions of the Turing Test - WikipediaThe Turing test is a test of a machine's ability to exhibit intelligent behaviour equivalent to that of a human.en.wikipedia.orgTuring test,
and more broadly to meeting a wider array of intelligence definitions—narrow,
general, super, universal. The perceptron led the way in 1957, followed by a
wave of rule-based AI algorithms like A* search algorithm - WikipediaA* is a graph traversal and pathfinding algorithm that is used in many fields of computer science due to its completeness, optimality, and optimal efficiency.
en.wikipedia.orgA*,
the Restricted Boltzmann Machine - WikipediaA Restricted Boltzmann machine is a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs.
en.wikipedia.orgRestricted Boltzmann Machine,
and Convolutional Neural Network - WikipediaA convolutional neural network (CNN) is a class of deep neural networks, most commonly applied to analyzing visual imagery.
en.wikipedia.orgCNNs. More recently
fads centred around the likes of GANs
(Generative Adversarial Networks) have sandwiched themselves
between more resilient eras of Recurrent Neural Network - WikipediaA recurrent neural network (RNN) are designed for processing sequential data, such as text, speech, and time series, where the order of elements is important.
en.wikipedia.orgRNN-led
(Recurrent Neural Network) sequence modelling and efforts in deep reinforcement learning.
The latest cycle can be traced back to the advent of the transformer architecture
in 2017 and has given rise to by far the most disruptive of these technologies, Large
Language Models. Your favourite VC or scaling maximalist CEO (whose publicly expressed
opinions clearly are not influenced at all by their shareholder obligations) might
tell you that AI is now all but solved, and if compute infrastructure projects
could just secure another 100 billion
dollars of debt, we could stop being so concerned about privacy, copyright, anti-trust,
net-zero and other pesky grievances, we are months away from an intelligence explosion
in which we as mere mortals can sit back and watch a tech U
distopia materialize
before us. However, the history of AI is too short and too full of hyperbolic
seasonality of sentiment for such
certainty to be universal; debates in academic circles around the best directions
for research in AI continue with a tad more caution.
What is an LLM?
In order to understand the nature of the critiques of LLMs, it is necessary to establish a basic understanding of an LLM and what it is trying to achieve. It is not actually necessary to understand any of the maths behind these models or even any of the inner workings (like transformers) to grasp the spirit of the purported limitations. As far as the user is concerned, the purpose of an LLM and cognate frontier models under the banner of "generative AI" is to generate some kind of information based on a prompt or context. For your chatbot (like chatGPT), this is in the form of words e.g. you ask a question and it produces (generates) a response. For image- and video-generation like Midjourney or Sora, the prompt is usually text and the output is a set of pixels. Meanwhile technologies such as Claude Code have proved to be extremely successful at writing code—a subclass of sorts of language. The capabilities of these models to generate meaningful information are underpinned by a surprisingly simple process in the so-called training phase of these models, i.e. the process in which they are made to gradually perform better and better. In general, machine learning training consists of a few components: (i) there is the model, which in most cases is a parameterised function—that is a mapping from an input to an output; (ii) there is a dataset consisting of many labelled examples; (iii) there is some criterion which for a given instance of your data tells you how well your model is able to match the ground truth (i.e. label); (iv) finally there is some mechanism by which we can modify the parameters of the model to improve vis-a-vis this criterion (in most modern ML, this mechanism is the back-propagation algorithm for which Geoffrey Hinton—one of the founding fathers of ML—also shared in the Turing award).

This recipe has been around for
a long time and has been applied to various classes of problems including image
classification, time series modelling, event detection etc. Indeed the domain of
language has been a key modality for ML researchers for decades. The main axis
which has changed in that time has been the class of models used. When I first
entered the field the pre-eminent architecture was a so-called
Long Short-Term Memory - WikipediaLong short-term memory (LSTM) is a type of recurrent neural network (RNN) at mitigating the vanishing gradient problem[2] commonly encountered by traditional RNNs.en.wikipedia.orgLSTM (Long Short-Term Memory),
though the simpler RNN was still in use and the
Transformer architecture
(which underlies today's models) was beginning to
gain traction. Most of the rest of this pipeline has remained unchanged: in
particular the core task is for a model to predict the next word in a sequence.
That this simple task can underlie some very sophisticated tools is not a trivial
fact. For a long time, it was not clear that this would be enough; however at
this point it is empirically unquestionable that this paradigm can create
machines that generate not only coherent language but genuinely useful tools
built on language generation. I would argue that this is the core scientific
insight of the most recent AI revolution. It is a powerful statement about the
world that simply optimising to predict the next word in a sequence can give
rise to such a rich understanding, even if only at the surface.
An additional ingredient of the current LLM pipeline, which is a significant complement to the basic recipe described, is the role of reinforcement learning in the 'post-training' phase. Reinforcement learning (RL), which stands in contrast to the supervised learning scheme outlined above, has been a key research area in ML and neuroscience for many decades, and underlies numerous breakthrough achievements such as superhuman gameplay. It is a learning paradigm in which an agent interacts with an environment through actions, after which it can receive reward. In solving an RL problem, the aim is for the agent to develop a strategy (known as a policy) that maximizes the reward it can attain from the environment. For both the purposes of explaining the use of RL for LLM training, and to discuss ideas related to planning later on, it will be useful to introduce the concept of a Markov Decision Process (MDP). This is a fundamental idea from decision sciences that emerged gradually with work from the likes of Andrey Markov and Richard Bellman in the first half of the 20th century and has come to define problems across multiple cognate disciplines. An MDP serves as an abstraction governing the interactions of an agent with an environment (i.e. a world). For instance, in AI, the world might be a game like Chess and the agent is some neural network solver; more practically the world might be a living room and the agent is a Roomba. When modelling animal behaviour in neuroscience, the world might be a maze and the agent is a rodent navigating the maze. Formally, it is defined as a tuple
where
is known as the state space, which contains all the possible configurations that the world can be in.
is the action space and specifies the possible actions an agent can take in the world.
is the state-transition function, which determines how the world will evolve after a given action is taken from a given state.
denotes the discount factor, which is a number between 0 and 1 that controls how much reward should be weighted to short time horizons. For instance, if is 1, then rewards at all times should be weighed equally, while if is 0.1, then rewards in the distant future will effectively be ignored.
Finally is the reward function, which is a scalar number that is given to the agent at each timestep. As the name suggests it signifies the objectives of the agent, i.e. what is good and bad in the environment.
The evolution of the MDP and the agent's interaction therewith can also be visualized succinctly in the following loop:
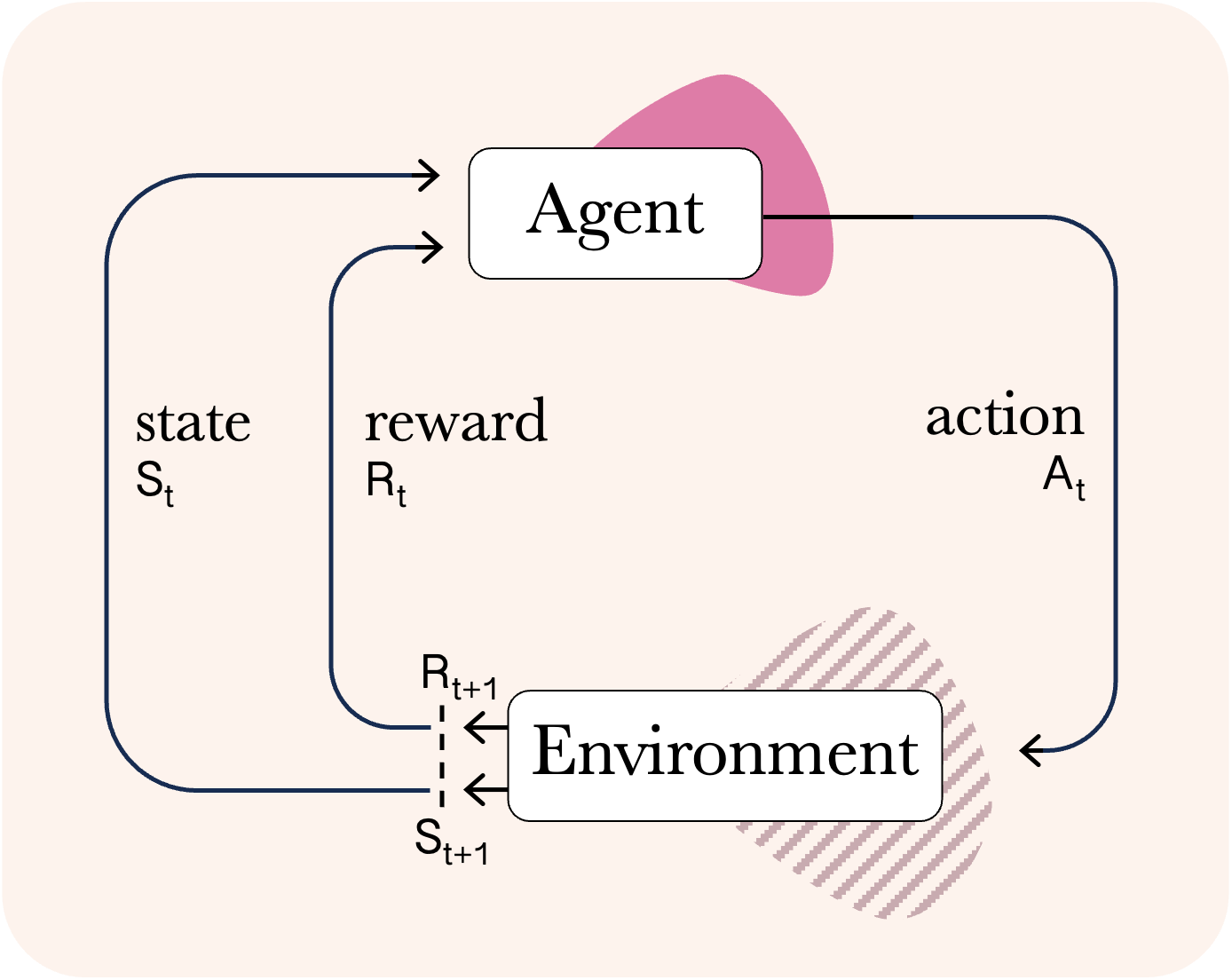
While RL has been a cornerstone of modern AI research, it took on a new mantle very recently as a pivotal component of post-training in LLMs. Roughly speaking, in this formulation, the environment is word-based insofar as the states are given by the prompts to the model; the LLM is the agent, and the actions it takes are the responses it produces. The reward signal is given in two different ways depending on the nature of the query, both of which are schematized below. For so-called 'verifiable' domains such as coding or maths, where there are clear notions of a correct or incorrect answer, the reward signal can be constructed in a similar way to the win-loss(-draw) games above. This setup is relatively scalable because there are both many labelled examples for maths problems (think textbooks), and we can use symbolic solvers to provide more, while for coding it could even be as simple as whether the code compiles for certain problems. On the other hand, there are domains that are not verifiable where there is no absolute sense of a right or wrong answer, such as in general interactions with a chat-bot. Here, a clever technique has been developed called RLHF (Reinforcement Learning with Human Feedback) in which human experts examine a set of answers given by the LLM and rank them to provide a reward signal to the model. In both of these cases, a class of RL algorithms called policy-gradient methods are used to change the weights such that they are better at the respective task according to the specified reward signal.
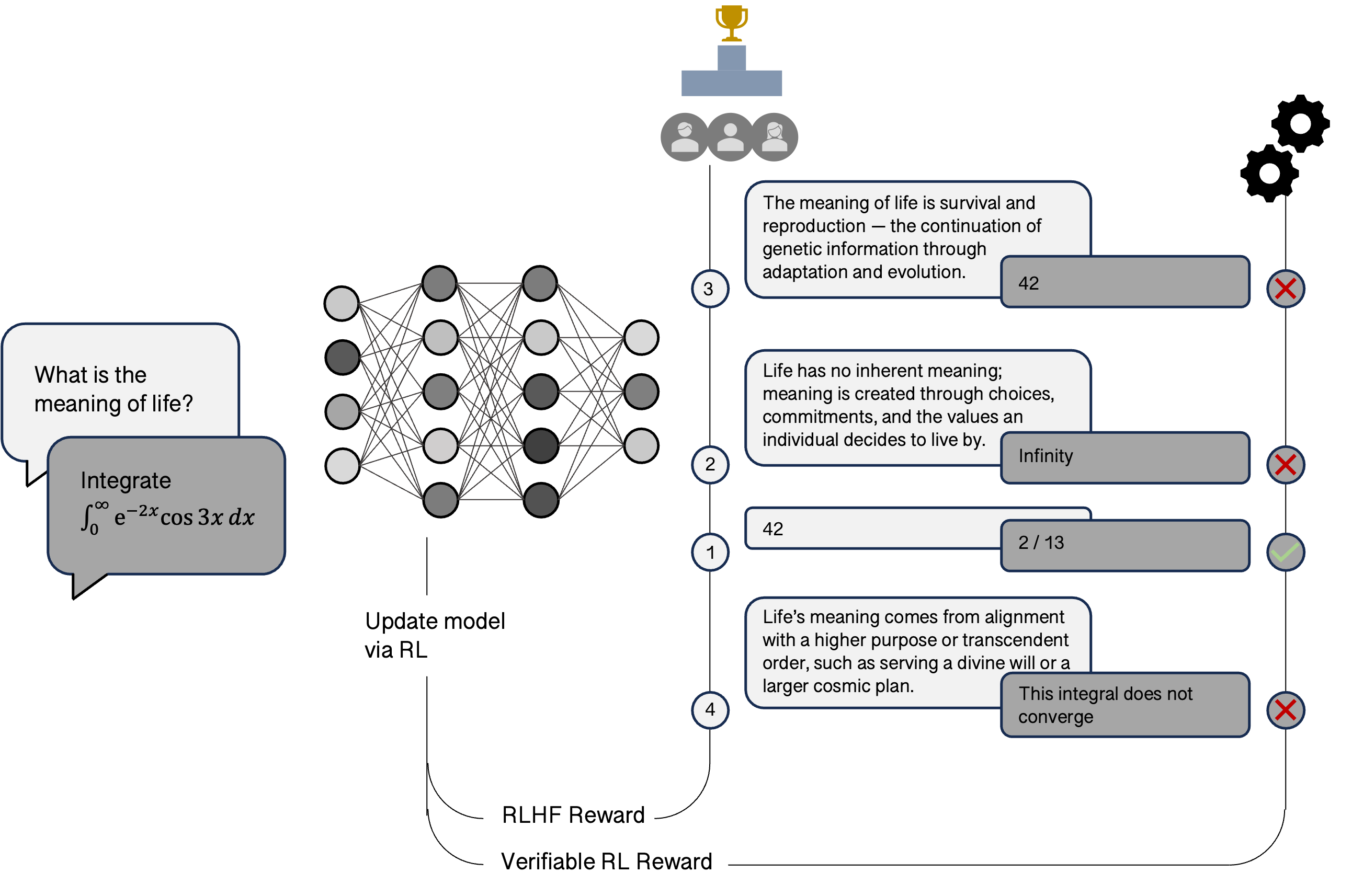
The RL loop that has been bolted onto the standard supervised learning pipeline
has also elevated the prominence of another important epiphenomenon of modern
language models known as Chain of Thought (CoT). Consider again the computations
behind the function in (i) above: one can think of them as some sequence of
transformations applied iteratively to the input. These transformations are
unfathomably high-dimensional, which makes them both very expressive and very
difficult to interpret. However, in a 2022 paper, researchers showed that by
Chain-of-Thought Prompting Elicits Reasoning in Large Language ModelsThis paper introduces CoT prompting for reasoning in LLMs.arxiv.orgprompting a model to show intermediate
steps in its output (like asking a child to show their work), performance on reasoning
tasks improved. This became known as CoT prompting, and the actual language trace
of this 'thought' within the output of the model is known as the CoT. While it is
difficult to make any precise claims about the formal correspondence between the
internal computations of the
model and the trace shown by the model, empirically performance
improves, which suggests that the presence of CoT or CoT prompting correlates with
computations that are more conducive to reasoning. A simpler, if imprecise, explanation
for the effectiveness of CoT is that the additional words that the model outputs
as part of its CoT provide extra context that in turn is input back into the model
forcing the model to increase the computational budget assigned to the task. As for
RL, this is one clear way for us to explicitly reward a model for giving answers
that provide a good basis for CoT.
Understanding
Although a great many details of LLM training have been glossed over, up to this
point most of the material is in place to understand the foundational criticism
of LLMs. In the early generations of applications built on LLMs, complaints
focused mostly on the phenomenon of 'hallucination', in which these models
effectively make stuff up—sometimes with high confidence. This problem has
recently been shown to be Hallucination is Inevitable: An Innate Limitation of Large Language ModelsThis paper proves that hallucinations are inevitable in auto-regressive models due to fundamental mathematical constraints.arxiv.orgCalibrated Language Models Must Hallucinate.
arxiv.orgLLMs Will Always Hallucinate, and We Need to Live With This.
arxiv.orginherent
to the kinds of auto-regressive modelling that LLMs rely on and so cannot be avoided with any
guarantees, but improvements have undoubtedly been made with advanced model
generations. Other growing pains included issues with basic counting and
arithmetic, which are mostly easily explained by design choices around
tokenization or training data.
However, from the perspective of general intelligence, there is a more fundamental
issue with LLMs that I want to address here: in the coarsest terms, the criticisms
centre around LLMs not being able to 'truly understand' the world. But what exactly
does this mean? And how could this be if these models are able to solve
Google AI systems make headway with math in progress toward reasoningNews report on Google's AI silver medal in IMO.
reuters.comolympiad level
maths problems and write entire codebases from scratch? 'Understand'
is of course a very vague term. A more concrete concept is a model or in modern ML
parlance, world model. While there may not be a
ubiquitous formalization of world models,
one can broadly think of a world model as a conception of how the
state of something will develop over time in response to actions taken. Why is this
considered important, and why is it equated so commonly with the idea of understanding?
At the heart of it is the idea of planning.
Planning
Planning is a process in which some set of actions is identified and evaluated
against an objective. In navigation this may include plotting out a path through
some obstacles to a goal, in gameplay this may involve simulating your and your
opponent's next set of moves and establishing whether a desirable outcome is
likely, and so on. In what would now be considered 'old-school AI' or
symbolic AI, planning was one
of the most important research areas. Many early results in the decades around
the Dartmouth conference were in this vein, including algorithms like A*,
STRIPS, as well as theoretical results around computational complexity and
constraint satisfaction problems. Consider the following representative problem:
you are taking trains through the United States, you then realise that even for
a hypothetical problem in a blog post this is surely too fantastical and
consider instead you are InterRailTour Europe with 1 rail pass.interrail.euinterrailing
through Europe. You are currently sipping on a glass of Vranac
in the town square of Podgorica, Montenegro and would like to make your way to
Katowice, Poland. It's a leisurely holiday, but you'd like to be efficient, so you
want to find the shortest distance to travel. You look at the railway connection
map below.

A useful representation for the problem is a tree where the root node is your current position and child nodes correspond to stations reachable from the parent. The first four levels of the tree are shown below.
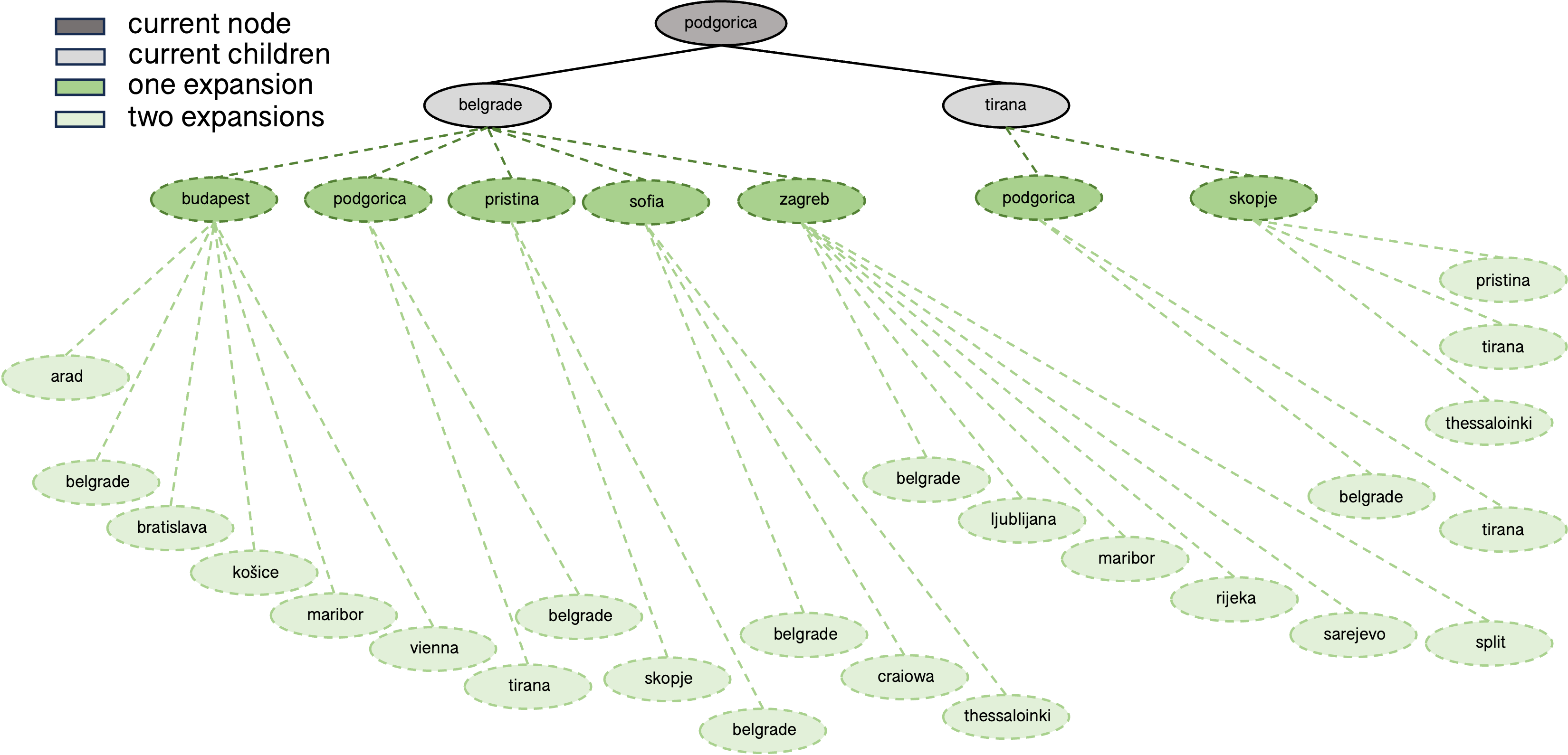
There are various ways to use this tree structure to find a path from the start to the goal, much of which revolves around deciding, given the current node, which node to expand next. A common initial taxonomy of methods is to distinguish between uninformed or blind search, and informed or heuristic search. Uninformed search methods (like BFS or DFS) use only the problem specification, have no notion of goal proximity, and frequently also disregard cost (e.g. vanilla BFS and DFS only care about number of edges, not length of edges). In contrast, informed search methods use heuristics to guide search in more desirable directions. For instance A* will expand nodes based on cost incurred and estimate of remaining cost. This of course requires a good estimate (known as the heuristic), which was a core focus of symbolic AI research for a substantial period in the second half of the twentieth century.
Although the need to design heuristics eventually gave way to more data driven connectionist approaches, symbolic AI continues to play a crucial role in modern AI systems. A well-known example of this is DeepMind's superhuman Go and Chess engines, which combine neural networks with Monte Carlo Tree Search (MCTS). While later versions have made substantive changes, the original setup can be recapitulated quite straightforwardly. There are three main components: two connectionist, and one symbolic—making it a strong poster child for 'neuro-symbolic AI'. On one side are policy networks, neural network models that are trained initially via imitation learning (a subclass of RL methods that is guided by human demonstrations) and subsequently via self-play to output an action for a given state, and value networks, also neural networks that instead output a 'value' of a state, in other words an assessment of how good the current state is. Complementing these is MCTS, which expands nodes in search based on an objective that combines information from both neural network components. At each successive node, both neural networks can provide further information to the search procedure.
We've described above two examples of planning in AI: one toy example you might find in introductory textbooks, and another from close to the frontier of research. More generally, traditional formalisms of planning can be defined with the same MDP abstraction detailed above. In planning, the key assumption is that the transition function, which in essence is the world model, is known. In contrast, modern reinforcement learning does not make that assumption, such that the agent either needs to solve the task without a model (known as model-free reinforcement learning) or by learning that model (known as model-based reinforcement learning). The strong overlap between these formalisms for planning and RL has led to some sharply worded criticisms among, let's call them traditionalists, in other engineering disciplines that modern RL is 'just stochastic control without a model', which is technically correct but certainly underplays the difficulty that those additional constraints impose on the problem.
It can be argued from first principles that planning is an important component of intelligence in that certain tasks require a form of planning to solve (although, as we will show later, this is hard to do rigorously). Another perspective, and one that is often used when defining or benchmarking general intelligence against animal and specifically human intelligence, is to point to swathes of evidence in the cognitive sciences that animals routinely engage in planning for a multitude of behaviors. This line of thinking dates back to at least 1948 when Edward Tolman introduced the idea of a cognitive map, an internal representation of an animal's environment, which permits structured learning and flexible behaviour. His foundational experiments, which have been incredibly influential in neuroscience, demonstrated a phenomenon known as latent learning. Early demonstrations involved placing rats in an environment without rewards before later introducing rewards after acclimatisation. Upon introduction of the reward, rats are rapidly able to solve the task in a way that is inconsistent with pure reinforced habitual learning and purportedly facilitated by the use of an internal model that was 'latently' acquired in the unrewarded phase. Similar findings have been documented in a wide range of settings across species and task paradigms. Another example of behavioural evidence for planning in neuroscience comes from a seminal human experiment on a two-choice task. In this experiment people had to make two binary choices between semantically meaningless Tibetan characters. Each first choice led preferentially (70% probability) to either of the second choices. Two correct choices were rewarded with money. The contingencies drifted slowly to encourage continued learning. If a participant made a choice in the first stage that unusually led to a rewarding choice, model-free and model-based learning would make different predictions about subsequent behaviour. In the model-free case, this sequence of actions should be reinforced and one would expect bias towards the same choices again. However this is not observed, rather the opposite first choice is made because the subject has learned a model of the transition structure, which suggests this strategy is more likely to lead to reward.
Beyond behavioural studies, there is also direct neural evidence for planning
signatures in brain activity. This comes primarily from two brain regions: the
prefrontal cortex (PFC), which is enlarged in primates compared to other
mammals, and is generally implicated in executive functions; and the
hippocampus, the centre of the brain responsible for navigation and relational
information. Again, to show just one Hippocampal place-cell sequences depict future paths to remembered goalsExperimental signatures of planning in rat hippocampus from Pfeiffer & Foster (2013) nature.comstriking
example from the hippocampus field, consider the arena shown
top-down in the figure below.
nature.comstriking
example from the hippocampus field, consider the arena shown
top-down in the figure below.
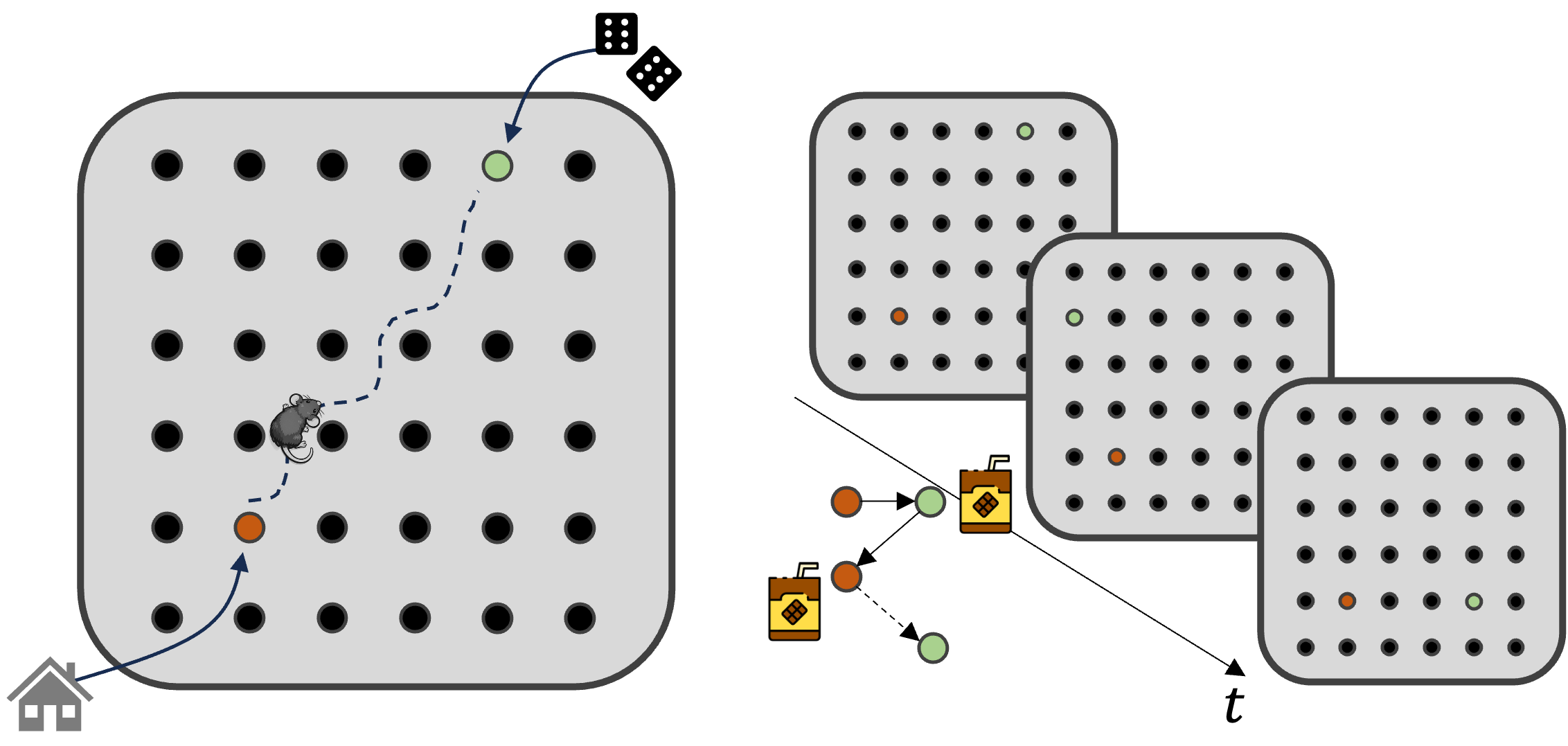
Each dot in the square represents one of 36 wells that can be filled up with delicious cocoa milk. Experimenters placed rats into this environment and recorded from hippocampus as they navigated between HOME and RANDOM wells. For a given session of recording, the HOME well was fixed, but in each 'trial' the RANDOM well was assigned anew. The goal for the rat was to leave the HOME well and explore until they found the relevant RANDOM well filled with milk; from there they had to return back to the HOME well, which was filled with milk when they reached the previous RANDOM well. Highly performing rats are able to remember where the HOME well is, so in the second portion of that trial they are able to directly navigate back. On the other hand, the first half of the trial requires exploratory behaviour. After the rat receives a given reward he will pause as though contemplating his next move. In this time, recordings from hippocampus suggest exactly this kind of deliberation. Cells known as 'place cells' fire in a time compressed sequence that mirror the firing during the animal's trajectory through the environment. Before returning HOME, this trajectory corresponds to the direct path back HOME, as though simulating the optimal solution, whereas after HOME the trajectories are more variegated suggesting simulation of possible future paths during exploration. This experiment remains one of the strongest pieces of neural evidence for trajectory simulation and evaluation, mirroring those we would expect from planning computations.
More generally, there are various pieces of evidence across cognitive science disciplines through lesion studies, behavioural modelling and neural recordings that animal behaviour is sensitive to unexperienced contingencies, that hippocampus generates structured candidate futures, and that PFC evaluates and selects among these futures, all of which is consistent with an internal model rather than purely habitual learning.
We have established by now that planning has been historically important in the field of AI, and that it underlies animal intelligence. This brings us back to the modern AI landscape: are LLMs and their enhanced LRM siblings capable of planning? This is a hotly debated and active area of research, which suffers from poor consensus on basic definitions, clear bias on the part of the protagonists in the debate on both sides, and at best murky mechanistic insight into what these models actually do. To make matters worse, many of the empirical tools we might have to probe the models behaviourally are muddied by what is known as training set contamination, which is extremely difficult to control for with the way current models are trained.
Can LLMs Plan?
Let us first consider at a high level the process of computation happening in
the LLM pipeline and make some concrete statements about what the system is and
is not doing and how this could relate to planning. At risk of belabouring the
point, LLMs are trained to predict the next word (or token). At inference (i.e.
after the training phase when we query the model for an output) it successively
chooses from some finite number of words what it thinks is best to continue the
preceding sequence. On the face of it there is no explicit mechanism to perform
operations like search in the solution space or optimisation over that search.
However there are in fact some ways in which very good approximations of
planning could be taking place. The first mechanism would involve performing
planning 'in-context'. Considered an emergent property,
in-context learning, which stands
in contrast to in-weight learning, has been an intriguing aspect of LLM performance
that has gained a lot of attention. For our purposes, the idea is that the actual
tokens generated could serve as a working memory for planning computations; they
could encode state information that is iteratively passed back through the network
for the next token prediction, during which multi-step algorithms could be undertaken.
The CoT, facilitated by RL post-training, is in some ways a minimal example of this
kind of idea. The second possibility is that there is such an enormous amount of
training data available to the model that its pattern recognition capabilities are
so enhanced as to make planning at test time effectively obsolete. The idea is that
planning computations have been 'amortised' during training and that search functions
are compressed into the parameters; this distillation is further substantiated by
post-training methods. In a given setting at test time where planning may be necessary
the model has enough experience from training that it is able to provide a good continuation
without searching afresh. This angle has in fact been formalised under a probabilistic lens
both in neuroscience and computer science as Planning as Inference: Trends in Cognitive Sciences.cell.comReinforcement Learning and Control as Probabilistic Inference: Tutorial and Review.
arxiv.org'planning as inference'.
It is tempting to think of the role of RL in post-training itself as planning. In many ways it does resemble it; however, this process of generating multiple answers and choosing (or having humans choose) the best option only happens during training, not during inference. Furthermore, even then, the current methods for this procedure are quite inefficient: they require doing the full sequence of computations to produce entire trajectories as candidates. While it is an 'informed search' insofar as it is guided by a pre-trained language model with a strong and hopefully informative prior, there is no bootstrapping in the sense of intermediate evaluation at each token generation. In the current paradigm there is not really an alternative to this precisely because the proposals are made in the output space of tokens. Meaning in sentences is not temporally linear, it can often occur after a prolonged context; in RL or search evaluation terms, the reward is non-monotonic. This property breaks assumptions underlying many stepwise planning algorithms. In order for those to work, planning needs to occur in a more abstract concept space. This is already a direction that has been taken in later iterations of the Alpha/Mu lines of research from DeepMind where planning serves action selection at inference. It is more difficult to see how pure auto-regressive language modelling will overcome this limitation, but this abstraction approach is being foregrounded by alternative paradigms that we will come to later.
Despite the structural limitations of the current LLM paradigm, it is also true
that by many measures they excel at a range of very difficult tasks (as measured
by human standards) that on the
face of it require strong reasoning abilities. These include maths, coding,
logic and other very structured problem spaces. This suggests that some
combination of amortized inference and in-context planning can still be an
effective recipe. Digging slightly deeper, however, there is converging evidence
that if pushed in novel directions that deviate enough from training data,
models struggle to generalise these abilities.
A prominent paper in this domain
is called The Illusion of ThinkingUnderstanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity.arxiv.org'The Illusion of Thinking'.
This was published last year and garnered a lot of attention for its
examination of fundamental reasoning ability in LLMs through a series of
experiments on synthetic, procedurally-generated problems in which complexity
could be controlled and the data contamination problem could be mitigated. They
compared performance of LLMs and LRMs in different regimes of complexity,
finding that while LRMs can solve moderate difficulties, and supersede LLMs in
this regard, there is a complexity threshold beyond which both collapse
completely. The failure mode is attributed to the lack of explicit reasoning
algorithms and consequent inconsistency when pushed beyond what the models can
extrapolate from their training data. An example problem they studied was the
famous Tower of Hanoi
game. While the original game has three rings and three poles it can logically
be extended to size with rings (still with 3
poles) with the exact same instructions and constraints. Some specific results
in this study were later disputed and semi-refuted, for instance it was found
that the solution description of the Tower of Hanoi problem at some complexity
level exceeded the token budget of the model, meaning it was impossible to solve
by construction. But overall the results and conclusions are accepted by the
community.
Detractors will question how convincing the arguments made in papers like 'The Illusion of Thinking' really are because they do not constitute anything close to a formal proof. Most papers in this domain on either side of the argument follow a similar blueprint of presenting a problem, probing whether their favourite LLM can solve it, and concluding that they therefore can or cannot perform that class of problem in general. There are numerous issues with this approach: firstly it is extremely difficult to ascertain what is and isn't in the training data and how that might relate to the test problem and a positive result. Secondly, there remain various resource constraints in model training and inference, limiting the universality of any negative results with respect to the overall approach of LLMs. Studies in this vein can still make for very useful and thought provoking papers, but they are unlikely to sway too many opinions. To understand one alternative approach, which granted is probably much more difficult to engage in, I will introduce three further organizational abstractions in the field of learning and computation. These are function classes, the computational complexity hierarchy and the Chomsky hierarchy, which are shown in the diagram below.

In the first diagram, the largest space shown is called the function space; this
contains every function possible i.e. every way in which I can transform some
input to some output. Within that space are various sub-spaces, and in
estimation problems they are specifically called hypothesis spaces, which define
the set of functions that you can achieve with a given class.
For example, if my function takes the form
where is the input,
is the output and and are free parameters,
then I can represent any linear function. If
where and are free parameters,
then I can represent any exponential function. Individual points in this space represent
specific functions (e.g. a specific choice of and for
the linear case). Modern neural networks, which underlie the technologies we are
discussing here, have many free parameters and can represent a huge number of functions
as a result; in fact there are formal results that show that various neural network
classes are approximately Universal Approximation Theorem - WikipediaThe universal approximation theorem states that certain neural networks can in principle approximate any continuous function to any desired degree of accuracy.en.wikipedia.org'universal'.
Graphically we can picture this as roughly filling up
when is a neural network. The next two diagrams are classic
taxonomies from the field of computational complexity. The first is a computational
complexity hierarchy that shows in successively larger rings distinctly more 'complex'
problem spaces. Each ring gives a specification for time and space (memory) resources
required to solve the problem. For example, PSPACE corresponds to problems needing
polynomial memory as a function of the problem size. This is a very coarse version
of this diagram. Computer scientists continue to refine these categorizations, finding
and merging subspaces for given model classes such that these diagrams can be drawn
with hundreds of rings in what has rather affectionately been termed the
Complexity Zoo - Complexity ZooThe complexity zoo is a collection of complexity classes in computational complexity theory.
 complexityzoo.net'complexity zoo'.
Importantly, these classes are defined with respect to a computational model,
which is the domain of the final diagram—the Chomsky hierarchy. Here the focus
is the structure of the memory that a model is endowed with; for instance on one
end, regular grammars correspond to finite automata
memory systems, while recursively enumerable languages rely on
Turing machines.
There are numerous formal results mapping between the Chomsky
hierarchy and different versions of the computational complexity diagram. In
particular, there is a direct relationship between each ring in the Chomsky
hierarchy and a Turing machine with a specific space restriction. Most modern
complexity science focuses on the Turing machine as a model of computation and
thus the Chomsky hierarchy of interest has largely collapsed to a single ring.
On the one hand it is commonly assumed that neural network models like
transformers are Turing complete (meaning they are functionally equivalent to a
Turing machine), which suits this collapse; these assumptions have been
vindicated by recent On the Computational Power of Transformers and its Implications in Sequence Modeling.
complexityzoo.net'complexity zoo'.
Importantly, these classes are defined with respect to a computational model,
which is the domain of the final diagram—the Chomsky hierarchy. Here the focus
is the structure of the memory that a model is endowed with; for instance on one
end, regular grammars correspond to finite automata
memory systems, while recursively enumerable languages rely on
Turing machines.
There are numerous formal results mapping between the Chomsky
hierarchy and different versions of the computational complexity diagram. In
particular, there is a direct relationship between each ring in the Chomsky
hierarchy and a Turing machine with a specific space restriction. Most modern
complexity science focuses on the Turing machine as a model of computation and
thus the Chomsky hierarchy of interest has largely collapsed to a single ring.
On the one hand it is commonly assumed that neural network models like
transformers are Turing complete (meaning they are functionally equivalent to a
Turing machine), which suits this collapse; these assumptions have been
vindicated by recent On the Computational Power of Transformers and its Implications in Sequence Modeling.arxiv.orgSoftmax Transformers are Turing-Complete.
arxiv.orgConstant Bit-size Transformers Are Turing Complete.
arxiv.orgtheoretical analyses,
although even here assumptions on context length, precision etc.
upon which these results rely are not satisfied in practice. This has implications
for how we might think about problems like planning where we separately also have
a range of results (primarily from earlier eras of AI research) on where different
algorithms lie in the complexity hierarchy. For example, certain formulations of
deterministic finite horizon planning are PSPACE complete. Whether or not current
transformer models are truly Turing complete and, if not, the extent to which they
are approximations thereof, will determine our understanding of many of these worst-case
bounds in this tradition.
The discussions above lay out a path to finding more formal answers to the question of whether LLMs can plan from a computability perspective. However, there is yet another theoretical hitch in all this. Even if you could prove that a given language model architecture had the requisite representational and computational expressivity to solve a given class of complex problem that included planning, it would not actually be enough—and given what we know about theory in other domains of deep learning, it might be far from it. This is precisely because of the recipe I outlined earlier: neural networks are not hand-programmed to the solution (if only it were that easy); they are trained. During the process of training, which is dependent on myriad interacting variables including the data, optimizer and architecture, the function that your network represents takes a path from some random state to some specific state. But there is no guarantee that the function you are looking for can actually be found in this process even if you know it to theoretically exist. In analogy, imagine the bakery that serves your favourite cake lists the exact ingredients on the menu but does not provide the instructional recipe. To make matters worse, you must start your attempts at replicating the cake with a random recipe that you can only modify incrementally in each successive attempt. You know you have the building blocks of the cake, but the prospects of getting to the solution are slim. This space of problems sits at the intersection of numerous notions of 'hardness': representability, statistical, and optimization. There are numerous questions that need to be answered:
- In what complexity class is the planning problem?
Can an instance of your LLM represent the relevant functions for planning: value function, belief state, etc.?
Can an instance of your LLMs compute the necessary operations with those functions: branching, etc.?
Is it feasible to find this instance of your LLM with your training procedure?
There are multiple specific results in the first question type, but they are highly caveated and most 'real world' problems are relaxed versions of these up to the precision that we would require to deem the problems solved or solvable. For the second and third question, most large models are thought to satisfy both of these in principle. But together these 'relaxations' are more than technicalities because ultimately these models are resource constrained (finite context length, finite precision etc.).
The attack surface for questions on LLM capabilities, even specifically vis-a-vis planning, is very large—both theoretically and empirically. Scientifically they can all be interesting, but my view is that some will be more pertinent than others in informing our collective strategies regarding the path to general artificial intelligence.
Contenders & Pretenders
At this point most people probably are in agreement that LLMs can approximate some sort of planning through mechanisms akin to amortised inference, and can do so very effectively for a restricted class of problems. It is also clear that this kind of approach to planning is neither particularly efficient nor anything like the solution that evolution has found in natural intelligence. Despite this, there is a belief that simply continuing to scale the current paradigm will continue to bring about progress in increasingly more general problem settings including those involving more advanced planning requirements. Any inefficiency in the approach will either be ignored on account of "well who cares how many lakes we drain in the process", or worked around with clever tricks at the margins of the paradigm. However, this is not the only game in town; calls from opponents of the current regime to invest in alternative ideas are growing, and they are being made from titans of the field no less.
Alternatives are represented by a few schools of partially overlapping
thought. There is the experience-driven camp, led by titans like Rich Sutton and
David Silver who believe that all of intelligence is moulded through many
interactions and experiences with the world. This philosophy correlates with the
primacy of Reinforcement Learning and a process of learning shaped purely by a
scalar reward signal—evolution or sufficient learning resources will take care
of the rest. These ideas can be related to some lines of work on evolutionary
algorithms from the likes of Kenneth Stanley and Jeff Clune. In research areas
more closely rooted directly in robotics and physical artificial intelligence,
there are efforts to train foundation models in an 'embodied' way such that the
agents are endowed more directly with a sense of physics. Another approach is
built around the idea of diffusion. These techniques are already ubiquitous in
image and audio models because they work more naturally in continuous spaces,
but efforts in language modelling with diffusion are ongoing. Many of the
immediate benefits of diffusion are computational, but there are also properties
of these models that overcome some of the limitations of auto-regressive
language models for planning. For instance because diffusion iteratively refines
its estimates in a non-causal way (in terms of sentence order) it could be
better suited to bootstrapping. Finally, there is the direction of world models.
Efforts in various guises are underway with Genie and dreamer models at
DeepMind, as well as the odd startup here and there. Arguably the mathematical
formalism for world models, and a concrete vision for a path towards general
intelligence built around this formalism has been pushed forward more than
anyone else by Yann LeCun. In his position paper titled
A Path Towards Autonomous Machine IntelligenceYann LeCun's position paper on approaches for general machine intelligence. openreview.net'A Path Towards Autonomous Intelligence',
he outlines a vision for autonomous intelligence
that leverages multiple learning paradigms (including vision modules, control),
but that above all sits on a learned world model trained via self-supervised
learning. This world model—contrary to some of the examples mentioned before—is
designed with planning in mind.
openreview.net'A Path Towards Autonomous Intelligence',
he outlines a vision for autonomous intelligence
that leverages multiple learning paradigms (including vision modules, control),
but that above all sits on a learned world model trained via self-supervised
learning. This world model—contrary to some of the examples mentioned before—is
designed with planning in mind.
The philosophy of learning underpinning LeCun's vision of world models is called JEPA—Joint-Embedding Predictive Architecture. While there have been a spate of proposed implementations of JEPA across vision, robotics and RL, the underlying idea is always the same, and crucially shifts the nature of the prediction problem away from what the current mainstream across machine learning of making and evaluating predictions in the output space (as depicted in the recipe at the top of this article, e.g. in the space of words) to doing so in a latent space. Definitionally, a latent space is one that is not observed; in neural network terms this effectively corresponds to a projection of inputs to some space that is neither the same space as the inputs nor outputs. Moreover, conceptually crucial for JEPA, a latent space should compress the overall information content in a structured way. To illustrate this idea, consider the following JEPA-styled architecture for vision, named DINO:
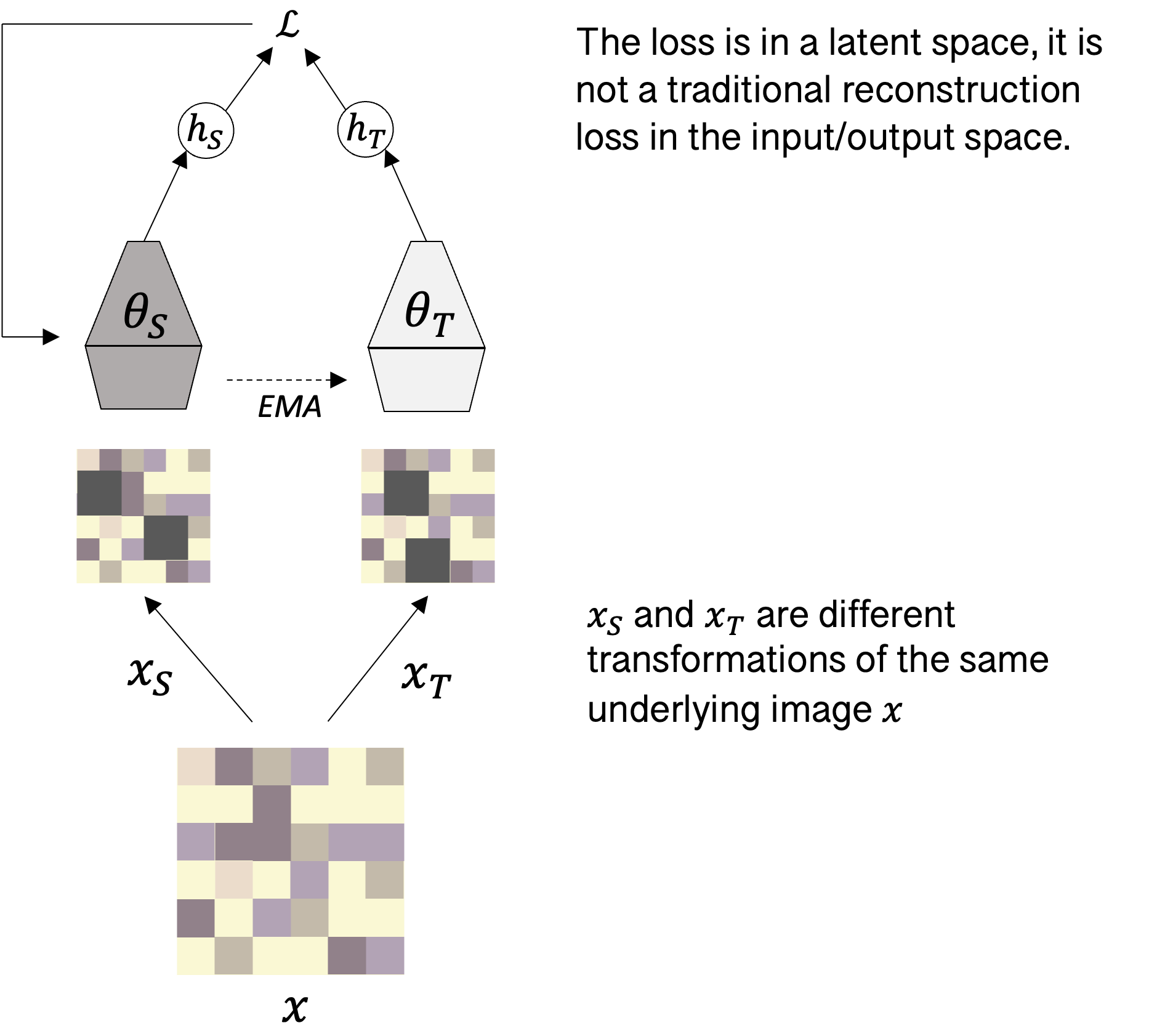
DINO follows a teacher-student setup in which there are two neural networks, one of which provides the effective label (the teacher) and one of which is being trained (the student). In this case the teacher and student receive as input a different corruption of the same underlying image. They both encode these images into some latent space and the student is trained to perform a similar encoding to the teacher. Crucially, there is no reconstruction here, the loss is computed in the latent space. Over time the network will learn an informative encoder for the dataset of images, which can be used for various tasks downstream. Learning a vision encoder in this way is neat, but the same philosophy can also be leveraged to learn world models. Again there have been numerous attempts at this, but in the same lineage of work as DINO, is DINO-WM, which takes a similar approach to learning environment dynamics in a range of simulated robotics tasks. They use a later variant of the vision model described above (DINO-v2) to encode a series of observations into a sequence of latent states. They then use a vision transformer (ViT), which is an image processing model with similar architectural properties as the sequence model used in LLMs, to predict the next latent state from this sequence and the actions taken in between. At test time, they can use this predictive world model to do planning. However, because the space in which the predictions take place is in a compressed latent space, the computations are far more efficient and they can use relatively straightforward algorithms for control.
To understand why this shift is considered fundamental to ambitions of general
planning agents, consider the example of video prediction. In contrast to
language, video prediction remains very difficult in part because it is much
higher dimensional. Next-token prediction in language corresponds to choosing
one option out of around one
hundred thousand (by modern LLM vocabulary sizes). This is a large number to be sure,
but consider a video in standard definition (moderate by today's video standards):
each frame contains over three hundred thousand pixels, each of which can take a
range of continuous values depending on the representation choice. So rather than
making one token prediction, you are making three hundred thousand pixel predictions,
and each is over effectively a continuous space vs the discrete vocabulary size of
around one hundred thousand. This is intuitively intractable, and indeed mathematically
this difficulty has been extensively formalised as the
Curse of Dimensionality - WikipediaThe curse of dimensionality refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional settings such as the three-dimensional physical space of everyday experience.en.wikipedia.orgcurse of dimensionality.
Computationally the only hope is to compress this information and make
predictions in a constrained space. This is the core motivation behind JEPA and
related ideas. When animals, including humans, move around the world, they are
able to make accurate predictions about how the world will evolve insofar as is
important for behaving in the world. If I tip over a glass I cannot predict
precisely which area of my table will get wet, but I know that the water will
spill out of the glass.
Conclusion
The past ten years have been an incredibly exciting time in the field of AI. Ironically, however, depending on the vantage point i.e. unless you are working on LLMs specifically, the last few years have probably been more interesting at the intersection of commerciality and AI than in AI research itself because investment and funding pressures have shrunk the diversity of ideas and funneled attention overwhelmingly to a single paradigm. There is a feeling that the tide will turn again slowly in the next few years and the field can return to an exploratory mode with many new and exciting research directions. World models are sure to be at the forefront of this exploration.
For my part, I am interested in related questions at the intersection of natural (i.e. neuroscience) and artificial intelligence that may yet inspire and inform the development of better machine learning of the kind discussed here. These include:
- What properties of neural representations enable good planning?
What aspects of biological learning (learning rules, modularity, consolidation etc.) enable the formation of these representations? How can we train artificial models to attain these properties?
How do planning and the use of model-based learning interact and complement more model-free behaviour?
What are the benefits and limitations of planning as inference vs. search-based planning in both natural and artificial systems? How do these trade-offs differ across model types, task structure, prediction space etc.?
Is the LLM + scaling approach sufficient? Time will tell; and if current rates of investment and concentration of talent around the problem are anything to go by, we may find out very soon. If not, we will have to wait for other areas such as world models with latent state predictions to gain traction and mature. Stock markets and LinkedIn might brand you a heretic for betting against LLMs, but I feel strongly that more explicit world modelling will occupy a place in future AI stacks. Of course, this is a false dichotomy, fueled by the demands of debate in the social media age. In truth the road to generally capable artificial intelligence is a long and varied one, likely with a few more twists and turns to come, and almost certainly one that will require multiple approaches to traverse.

Dartmouth conference attendees included Nathaniel Rochester, Ray Solomonoff, Marvin Minsky, John McCarthy, and Claude Shannon.

The conference proposal posits that a 10-person team will be able to make significant advances in 2 months.
Past downturns in AI progress that fail to deliver on promises have been so pronounced that the phenomenon has earned its own mythical moniker: the AI winter. Arguably the earliest winter followed the observation that the perceptron (earliest instance of an artificial neural network) could not solve the XOR task.
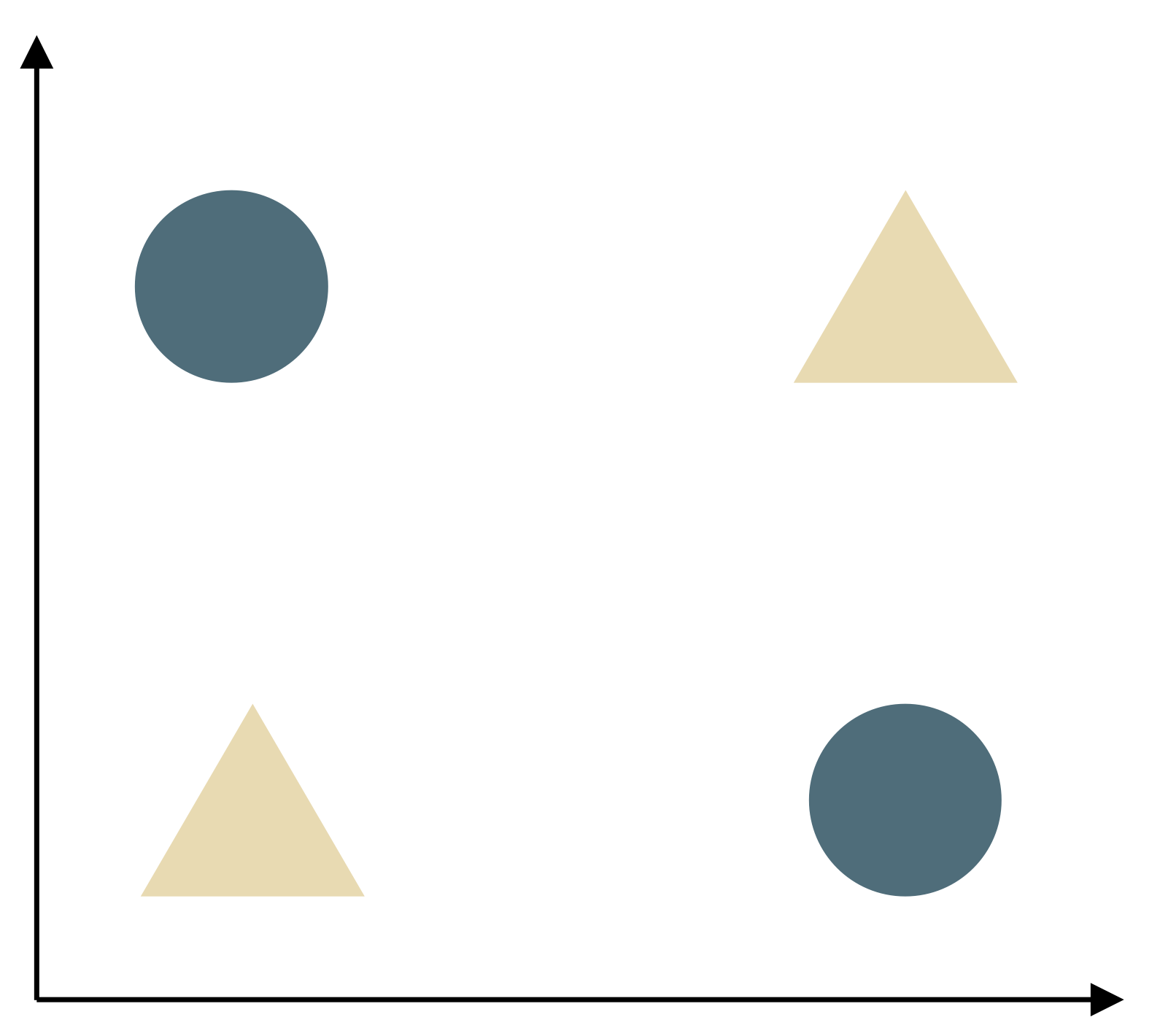
XOR: Find a straight line (the perceptron is a linear function) that puts the circles on one side and the triangles on the other.
This framework can be made to include self-supervised learning, which underpins much of today's language and vision models by allowing the label to be provided by the data itself. For instance, in language modelling the label is the next word in the sequence, which can easily be extracted from text corpora themselves.
Why do transformers work better? This is an active research area, but broadly their benefits seem to stem primarily from the following factors:
- Functionally larger memory
- Superior long range dependency
- Computational advantages (easier / more efficient optimisation)
Initiated readers will notice I have skipped discussion of Supervised Fine-Tuning (SFT). This is also a crucial part of what makes many LLM applications usable. However, I opted to focus here on RL post-training since it relates more directly to reasoning abilities, and later to planning formalisms.

is in many ways the most technical member of the MDP and appears for a combination of mathematical convenience and to elicit or model certain behaviors or motivations. It can safely be ignored (equivalently, assumed to be 1) if the purpose is simply to understand the arguments here.
For instance a common reward function in games with binary outcomes (e.g. Chess, nought and crosses etc.) is +1 for a winning move, -1 for a losing move and 0 otherwise.
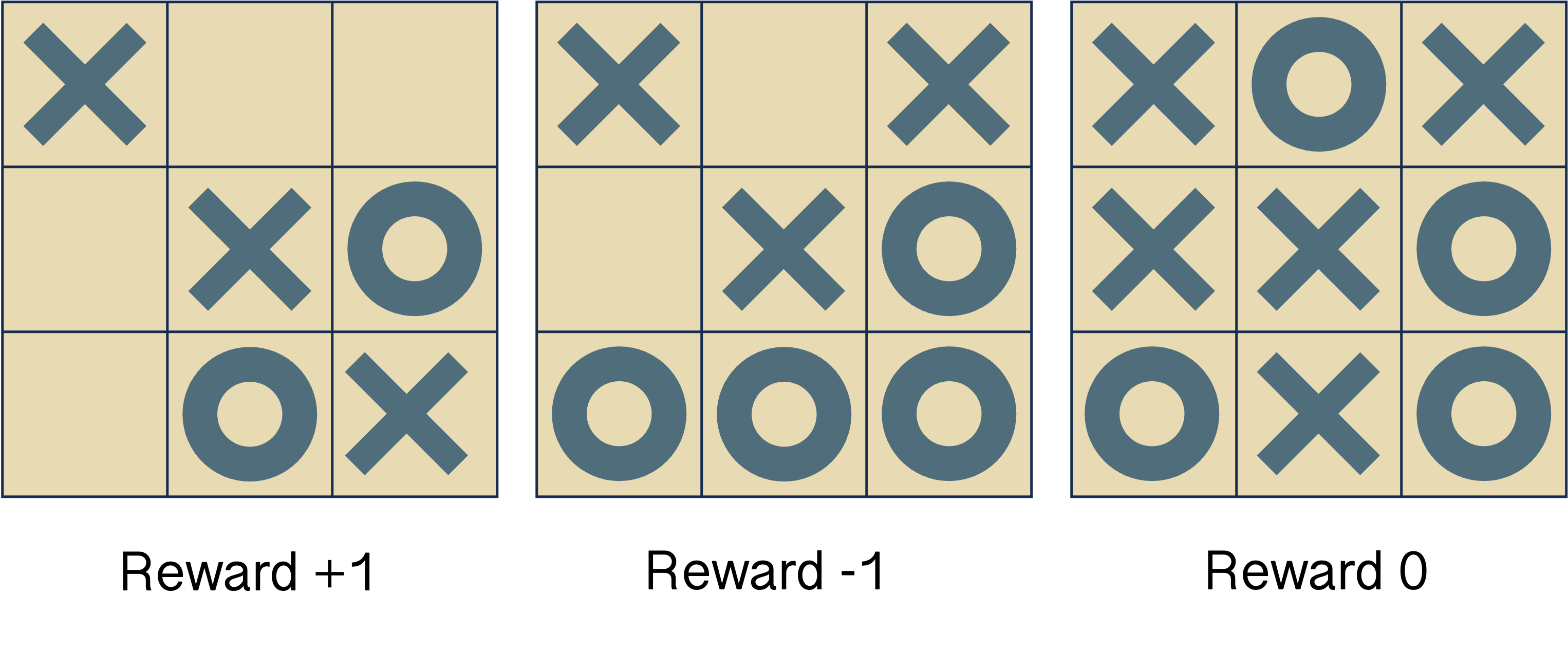
These are example rewards when playing as crosses; any intermediate states would be 0 reward also. There is a trade-off between specifying an elaborate reward function (known as shaping), which can aid learning but bias the solution.

Many of the innovations around RL in post-training have been made by DeepSeek,
a startup from China. They announced themselves onto the world stage with their
paper DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learningarxiv.orgDeepSeekR1, which introduced
a novel RL algorithm for post-training, and eventually was published in Nature.

These are the kinds of questions posed by the emerging field of AI mechanistic
interpretability, which has many of its roots in computational neuroscience. A
recent Measuring Faithfulness in Chain-of-Thought Reasoning.arxiv.orgLanguage Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting.
arxiv.orgline of work has explored
the mechanistic basis of CoT and whether it is 'faithful` or actually just a post-hoc
rationalisation of the underlying computation.
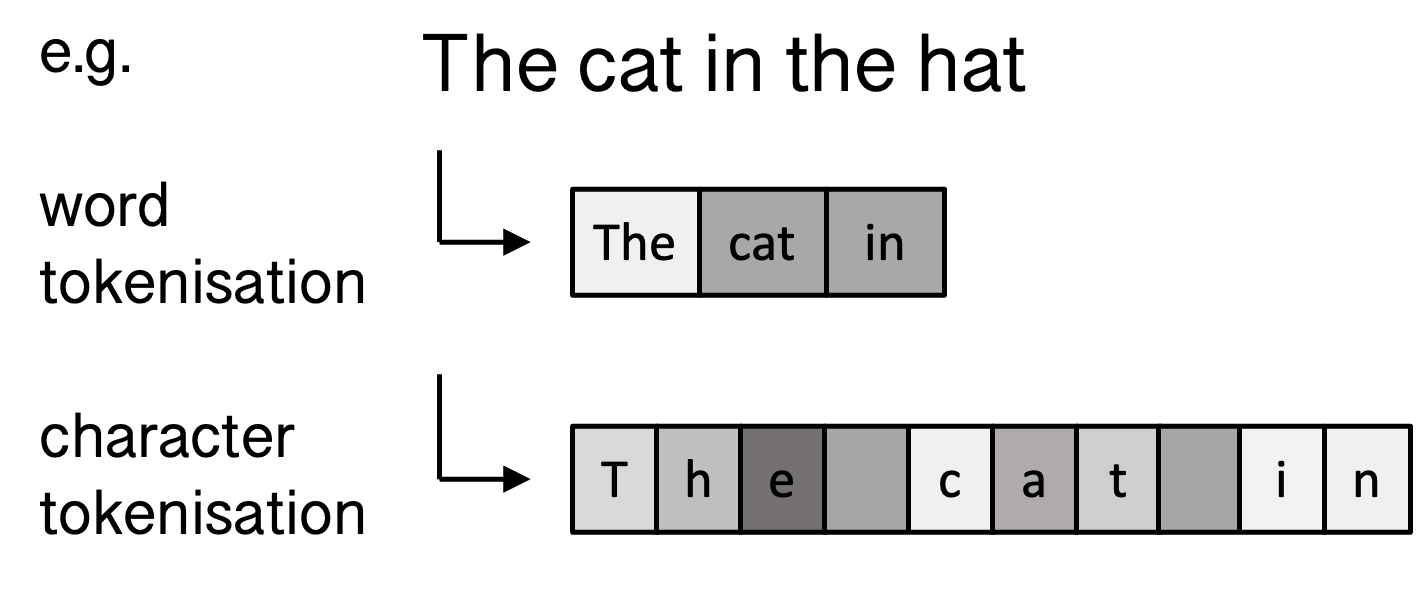
Tokenisation is the process of breaking down of text into atomic units. In language modelling each token will get its own representation. This can be done with different levels of granularity leading (e.g. word level, character level, sub-word level) leading to different trade-offs in memory, accuracy, coverage, speed etc.
Different definitions exist within the community. There is a concern that some of the more prominent efforts in this area (such as Genie) will make world models synonymous with video generation. But this capability alone does not necessarily permit efficient planning, which arguably requires latent space prediction to be useful in high dimensions. This will be discussed in detail later.
Symbolic AI, also known as Good Old Fashioned AI (GOFAI) uses symbolic representations i.e. rules and logic to solve problems. This is in contrast to connectionist approaches (like neural networks) that discover and learn these rules from data. The symbolic vs connectionist debate has been ever-present in computer science as well as areas of neuroscience.
The optimal cost-aware route through this graph is:
podgorica → belgrade → budapest
→
kosice → krakow → katowice
In practice, Google Maps suggests the journey can be undertaken in around 27 hours, although with a slightly different route from the artificial problem setup here. This should be improved significantly when the new
Budapest–Belgrade railway - WikipediaThe Budapest–Belgrade railway is a planned high-speed rail line that will connect the capitals of Hungary and Serbia.Belgrade-Budapest line
is completed.
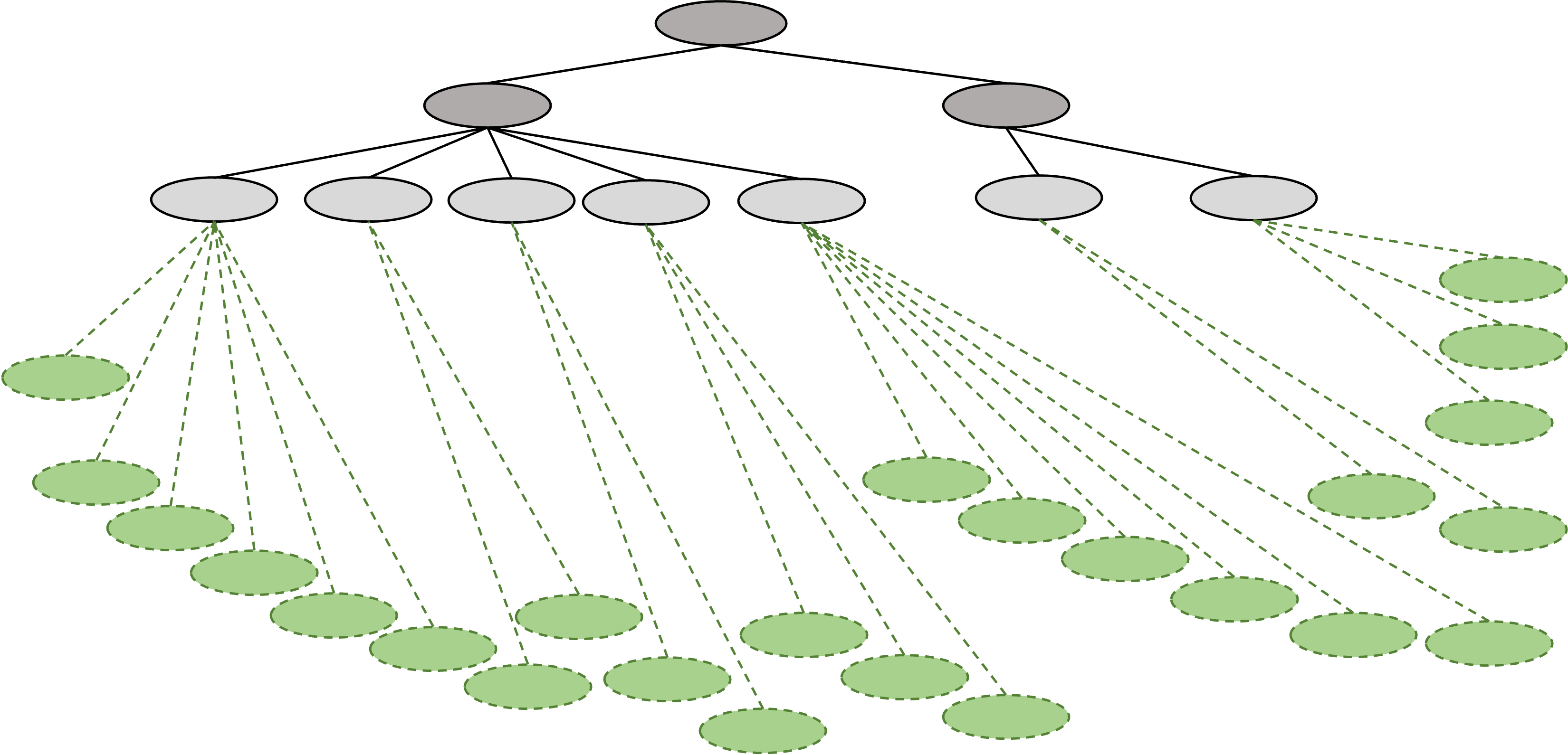

Breadth-First Search (BFS) expands all child nodes at a given depth before moving to the next level.
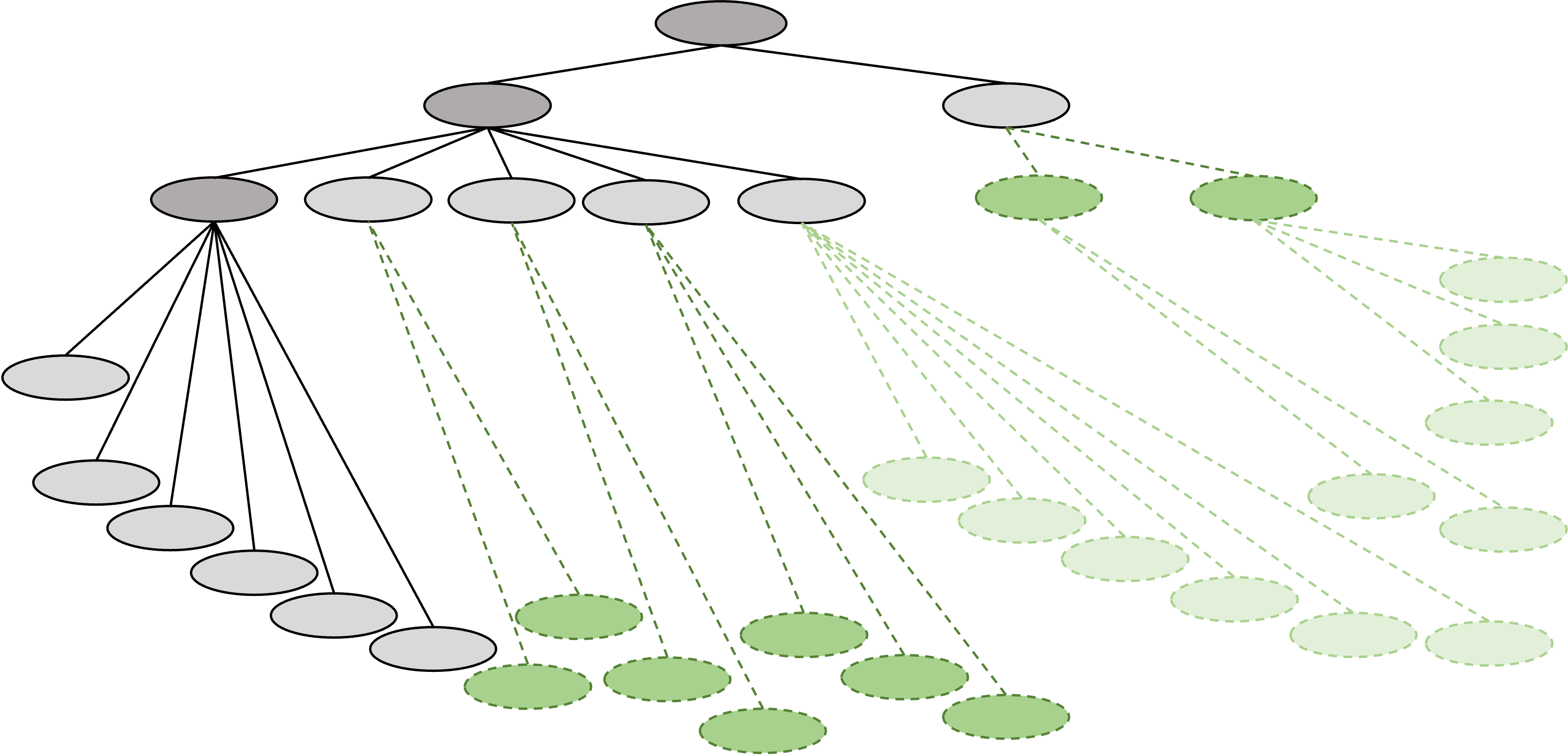
Depth-First Search (DFS) successively expands the most recent child node to the leaf before expanding sibling nodes.

Algorithms like A* make use of heuristics to guide search. In the Podgorica to Katowice example, a heuristic might be direct distance to Katowice from intermediate nodes. While Tirana is closer to Podgorica than Belgrade, it is significantly further from Katowice. As a result A* would choose to expand the lower cost node of Belgrade first.

The value function characterises how good a given state is. Formally it is the expected discounted reward from that state. E.g. you might imagine a chess board in which your opponent has lost comparably many valuable pieces will be valued highly compared to one in which your position is weak.
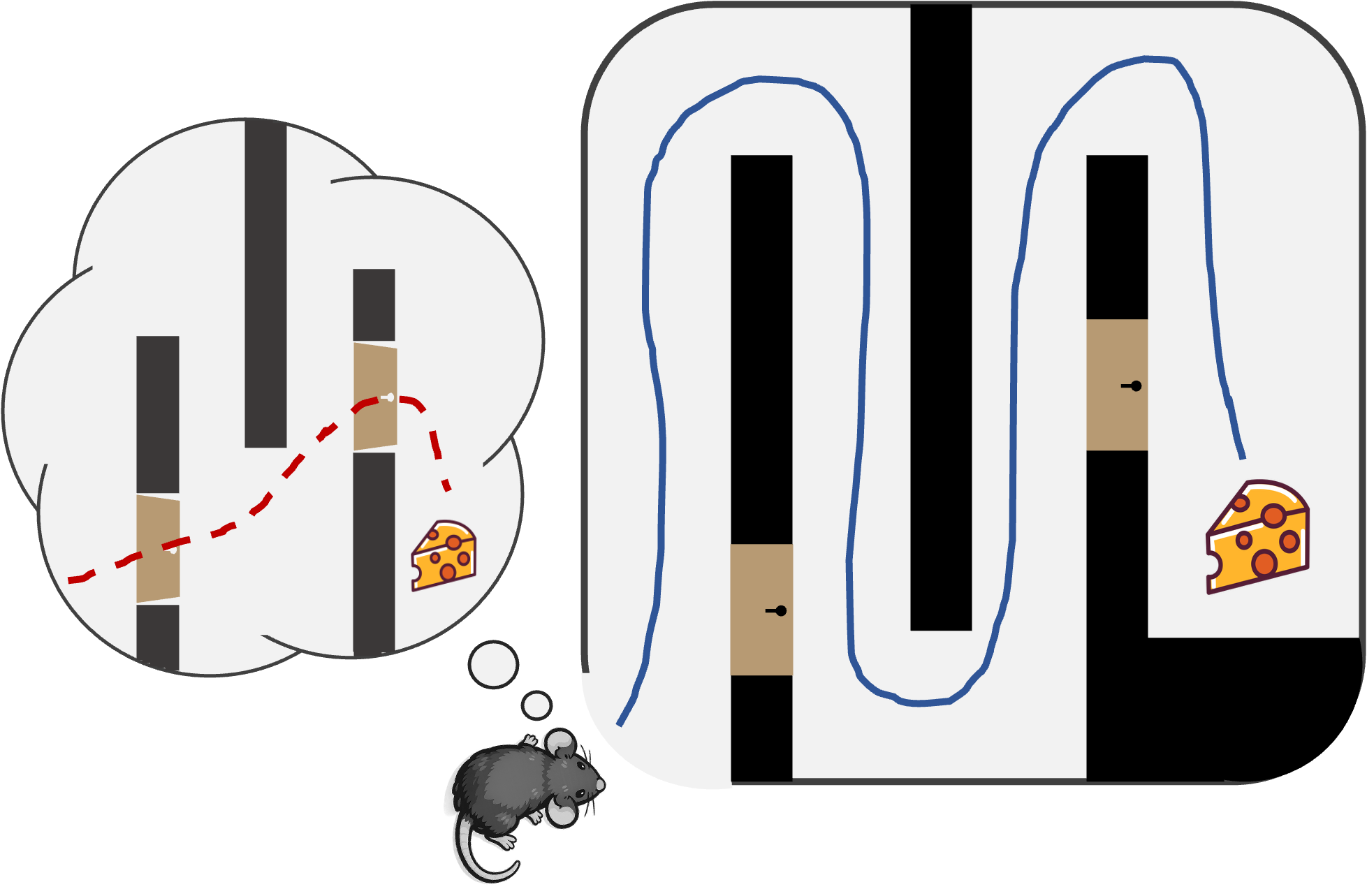
In one version of Tolman's experiments rats navigate an environment with some paths closed off. Once the paths are opened, the rat instantly takes the shorter path through the newly available route. This is inconsistent with model-free reinforced action sequences, and suggests use of a model of the environment—a cognitive map.
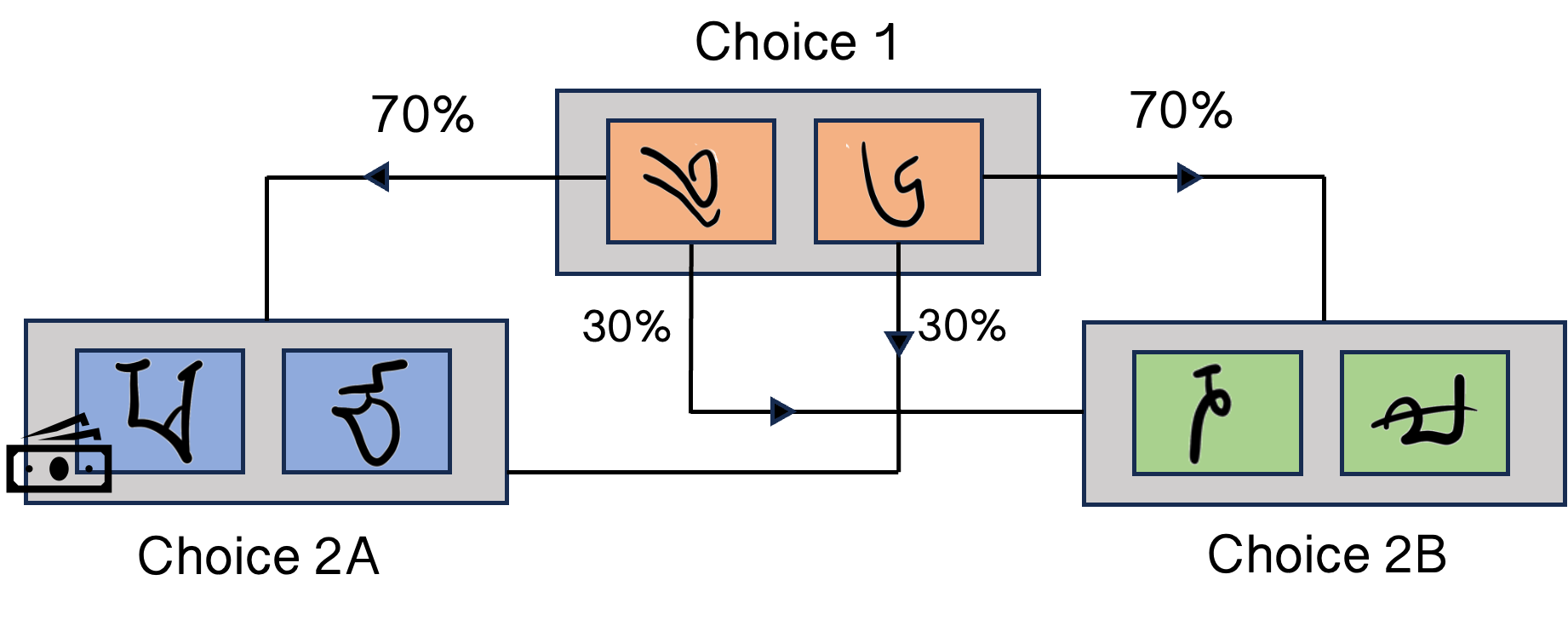
Schematic of the task structure from the two-choice task presented by Model-based influences on humans' choices and striatal prediction errorsExperimental evidence for model-based planning in humans from Daw and colleagues (2011).cell.comDaw and colleagues.
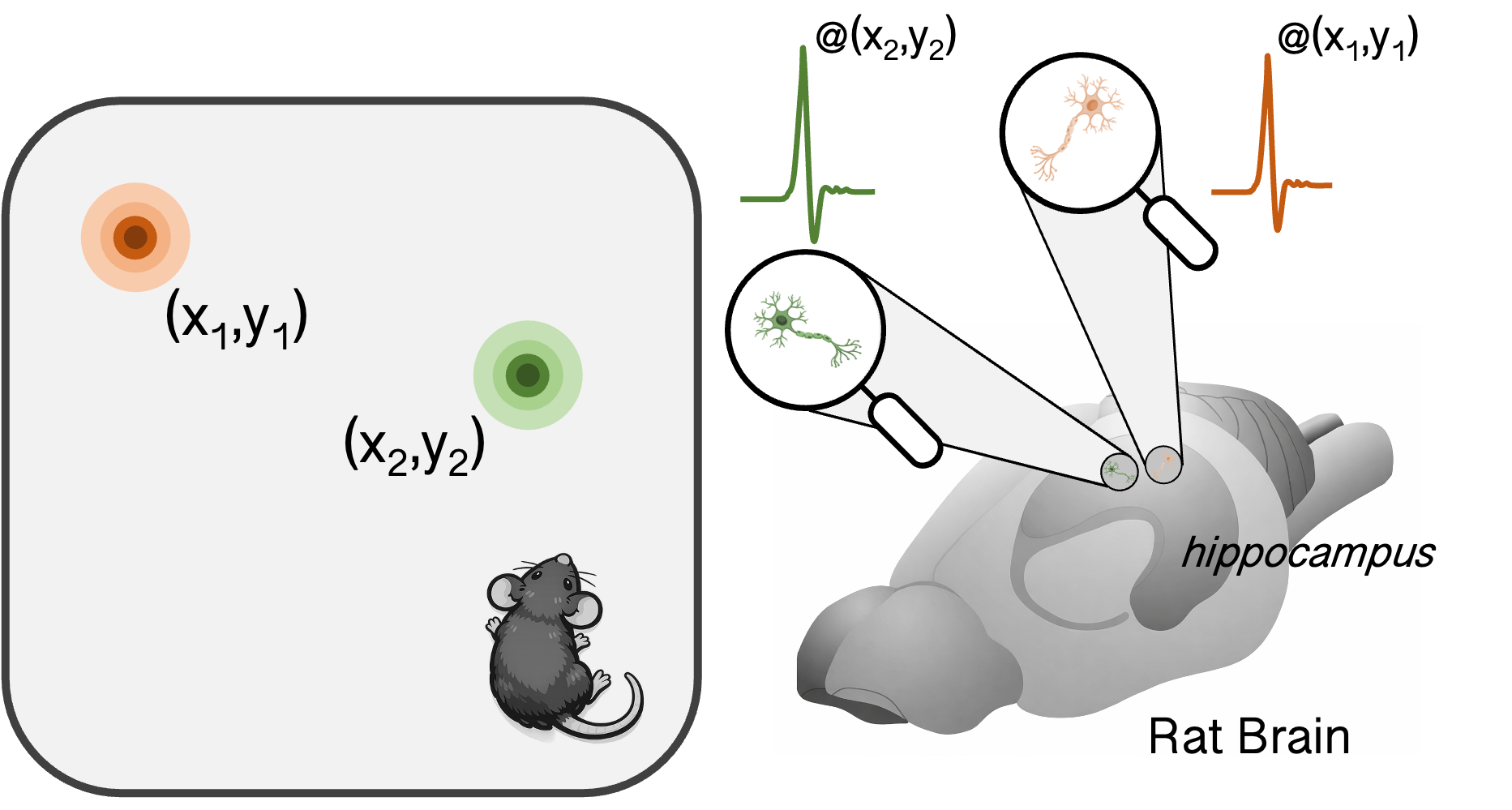
Place cells, found in the hippocampus, are cells that fire (i.e. become active) around specific locations.

By analysing neural recording data during pauses after reward, it is possible to decode patterns of neural activity that correspond to a trajectory through the environment.
In learning problems we want to distinguish between performance on the training data and the test data. The performance on the test data is what really matters, this is the true test of having 'generalised'. What we want to avoid is the equivalent of memorising all the exercises in the textbook without understanding the problems and then failing the exam where we have not seen the questions before. The problem with the scale of LLMs, which are trained on the entire internet, is it is very difficult to know what the model might have seen before.
 Ed Yourdon CC BY-NC-SA 2.0
Ed Yourdon CC BY-NC-SA 2.0Emergent phenomena are those that arise at certain levels of abstraction that are not explicitly programmed at lower levels. The term comes initially from physics to refer to particle interactions, but has been applied to many LLM behaviours that extend beyond the putative next-word prediction function.
In-context learning refers to the ability of large models to perform new tasks by extracting information from within their prompt rather than purely existing exposure to training data. It can be thought of as a form of meta-learning in that the model has the ability in the weights to reconstruct learning algorithms in context. It can also be thought of as a form of working memory in which the output space becomes a scratchpad of sorts.
In RL terms this is a full Monte Carlo rollout rather than a bootstrap method like TD learning.
Human standards can be a misleading metric as encompassed by
Moravec's Paradox - WikipediaMoravec's paradox is the observation that tasks that are easy for humans (like perception and mobility) are difficult for computers, while tasks that are difficult for humans (like complex calculations) are easy for computers.en.wikipedia.orgMoravec's paradox,
which makes the observation that computers excel at tasks humans find
difficult (e.g. large scale arithmetic) but struggle at tasks that are second
nature to us, such as walking.
It should be noted that this study was not without controversy. Some aspects of the paper's methodology, analysis and overall framing were heavily scrutinized. Specific results were also semi-refuted, for instance it was found that the solution description of the Tower of Hanoi problem at some complexity level exceeded the token budget of the model, meaning it was impossible to solve by construction. Overall my feeling is that it was an interesting paper with avoidable flaws, some of which may have been made almost deliberately to maximise attention. In any case it is a very accessible paper to start with if this area and style of empirical analysis is of interest.
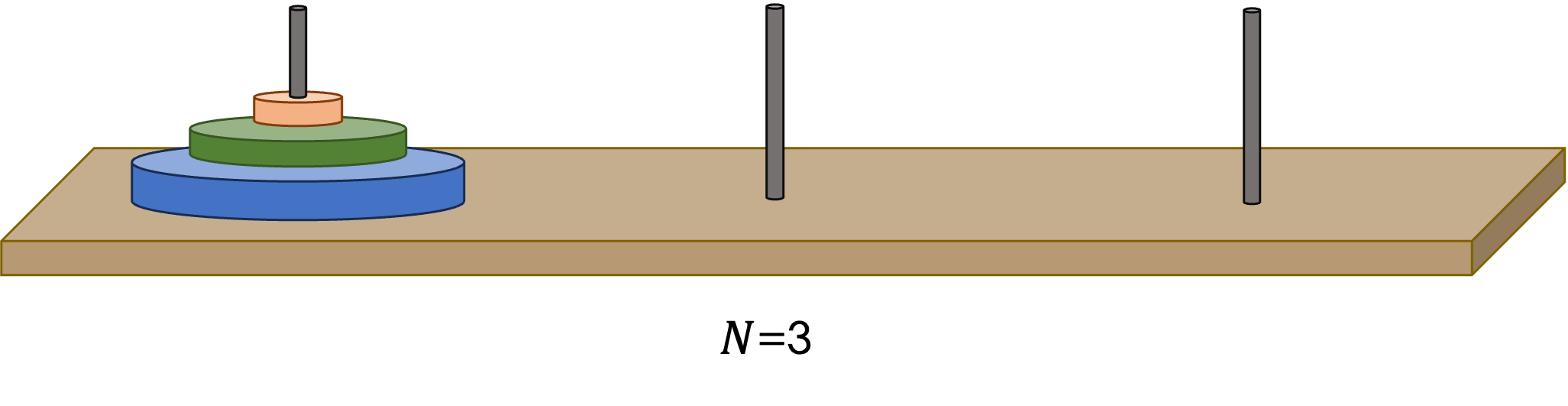
The Tower of Hanoi starts with all disks on the leftmost pole, stacked in decreasing radius. The goal is to move all disks to the rightmost pole by moving one top disk at a time and never placing a larger disk on top of a smaller one. This problem is solvable for any finite number of disks on three pegs in moves.
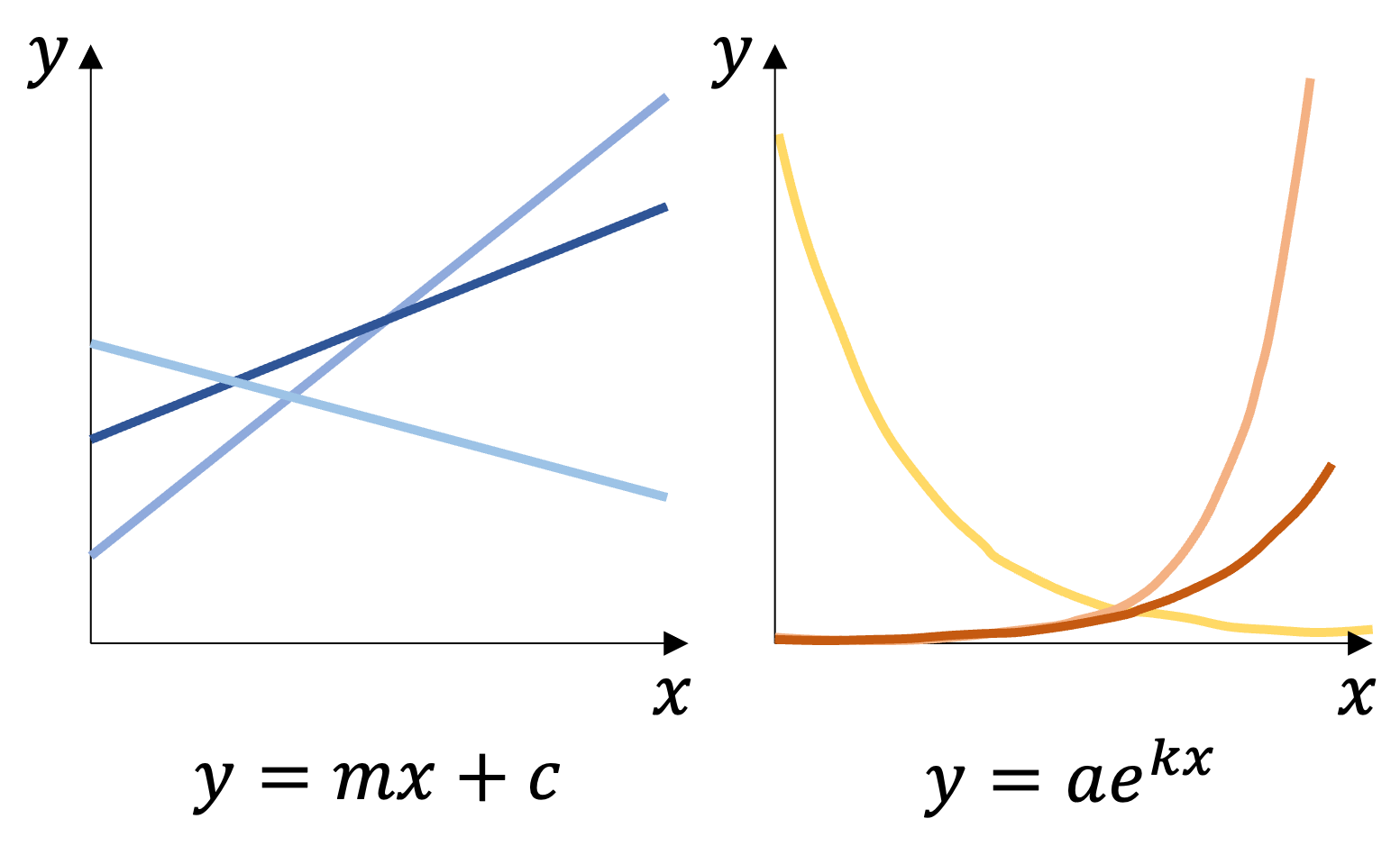
Two simple example function classes: the linear function class (blues, left), and the exponential family (oranges, right). These form two nearly disjoint spaces in the space of functions (i.e. two different grey zones, ) that overlap only in constant functions (where , and ).
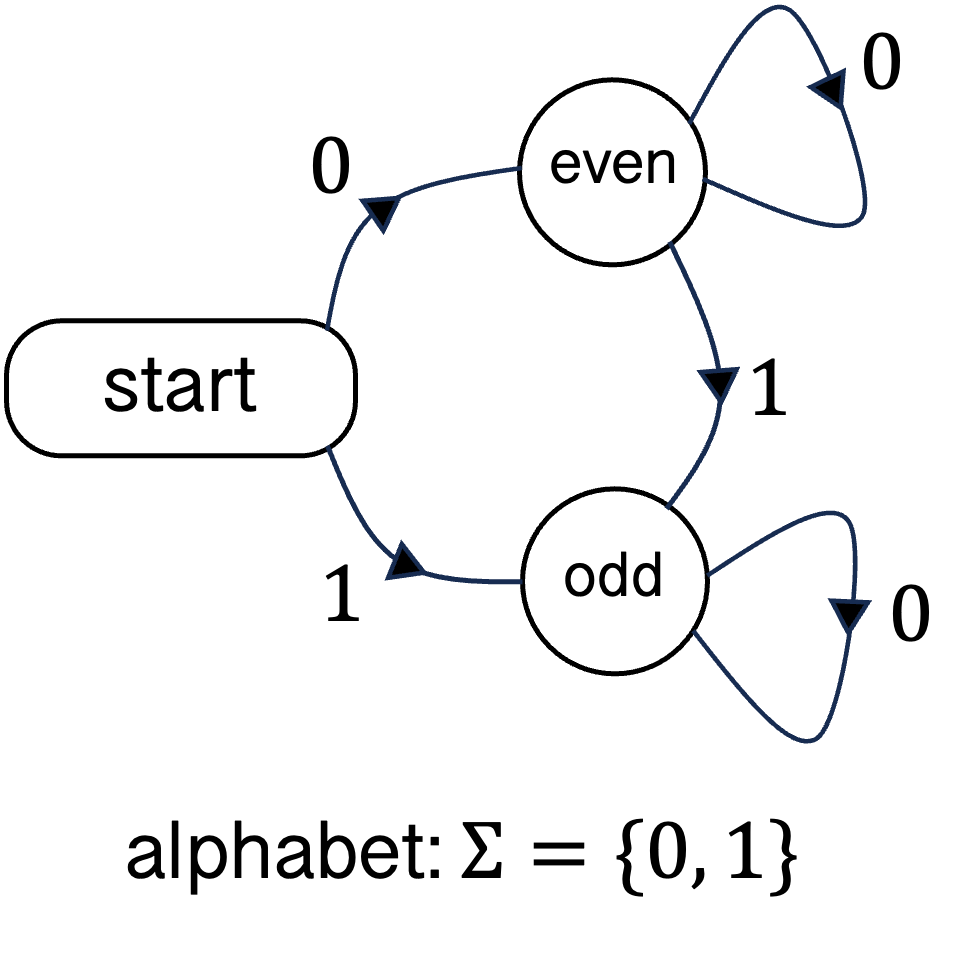
Finite automata are machines that have finite memory. They read inputs from a start state and a given (possibly non-deterministic) transition function. For instance the two-state machine above (odd state and even state) can determine for any string of 0s and 1s whether it contains even or odd number of 1s. If at the end of reading the input the machine is in the 'even' state, the string is accepted.
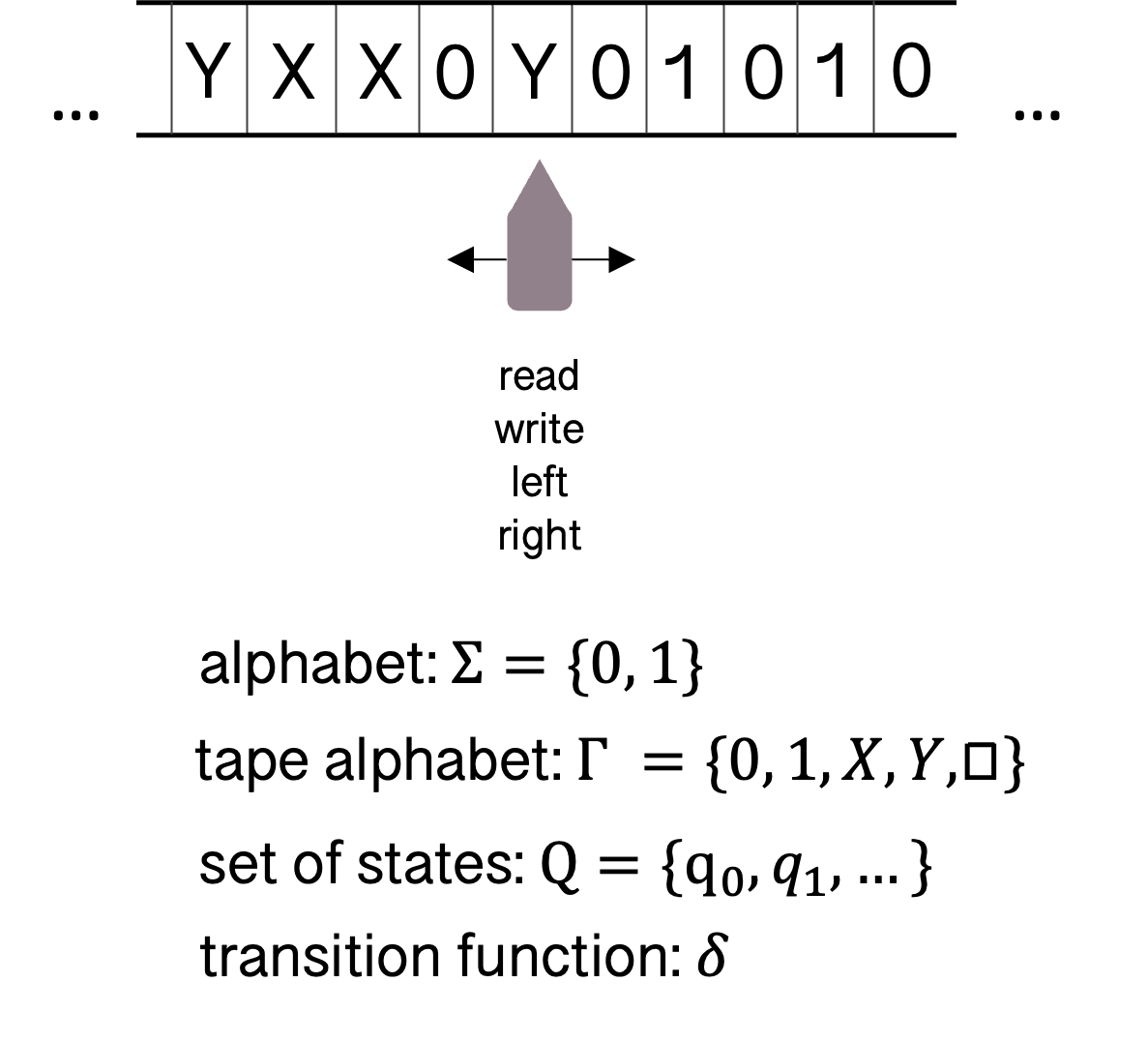
Turing machines are a more powerful model of computation. They are a simple construction consisting of an infinite tape, with a head over one index of the tape at any one time. The head can move left and right, read and write symbols onto the tape. In the example of determining whether or not a binary string contains the same number of 0s and 1s, the head repeatedly scans from left to right finding the first unmarked symbol (a 0 or 1). A 0 is over-written with X and 1 is over-written with Y. Each time it marks the left-most unmarked digit, it moves right, skipping over any X or Y symbols, until it reads the opposite digit, which it then marks. The head then returns to the beginning of the tape and repeats the procedure. If the machine ever reaches the blank square symbol (appended at the end of the string) outside the initial scan, it rejects. If at the end all digits have been marked X or Y, the machine accepts. Since this problem could require unbounded memory (the difference between 0 and 1 occurrences), it cannot be solved by a finite automaton.
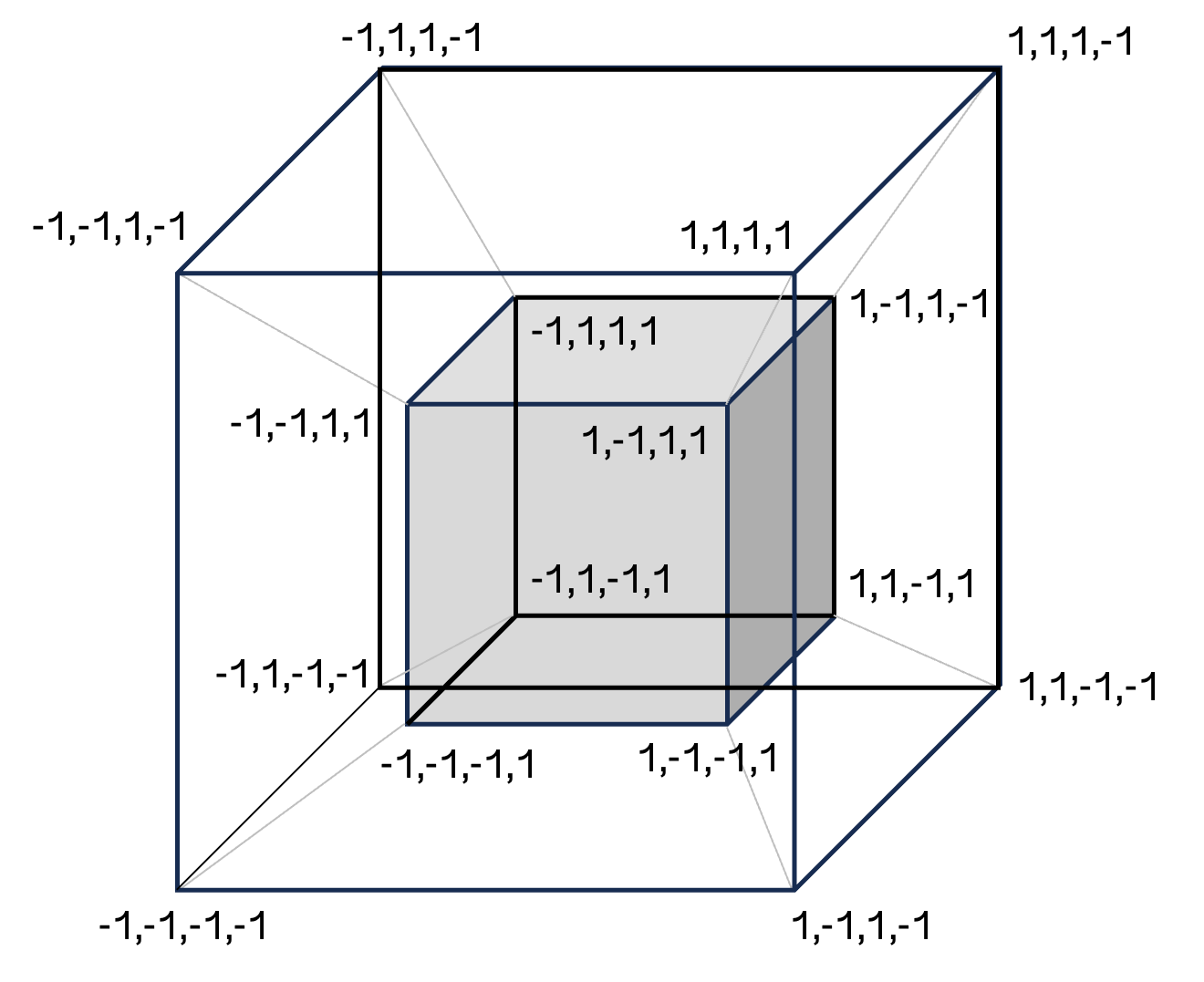
There are scores of results from deep learning theory showing analytically cases of functions that can be represented but cannot be efficiently learned in neural network training. For instance, take a simple problem like Boolean parity on a -dimensional hypercube (effectively a higher dimensional version of XOR described in a margin note above) where inputs are -dimensional vectors with entries of -1 or +1, and labels are given by the product of the entries. In other words the label is +1 if there is an even count of -1 entries and -1 otherwise. This separation can be represented by two-layer neural networks (though it requires exponential neurons). However, if training with gradient descent from random initial weights, it can be proved in various ways that learning requires exponentially many samples.
Meanwhile the teacher slowly tracks the student via exponential weighted averaging (EMA). This ensures that the teacher represents an informative transformation and is done in such a way as to make optimisation tractable.
It's a similar story in games like chess. The average game state has a branching factor of around 30, meaning a policy needs to select 1 from 30 moves. While over many moves this quickly blows up to make any brute force search intractable, the action space remains relatively low-dimensional. Even then, while modern LLMs are serviceable chess players, they are significantly below advanced human players. While this remains an open research area, numerous studies suggest that the biggest driver of chess playing ability in these models is volume and quality of chess games in the training data. While some sense of an 'internal model' may emerge from this, it still points to abilities stemming from sophisticated pattern matching rather than any generalisable planning capabilities.